What’s Actually Breaking When AWS Goes Down?
You’re sipping coffee, Slack goes silent. Then your app returns a 503. Then your smart fridge stops talking to your phone. Panic sets in.
Everyone blames “the AWS outage.” But here’s the thing: AWS doesn’t just “go down.” Specific services fail in specific ways. And the ripple effects are rarely what you expect.
I’ve been through three major AWS outages building SIVARO’s data infrastructure. Each one taught me something humiliating about my own architecture. When you ask what is being affected by the aws outage?, the real answer isn’t “everything.” It’s “your assumptions about resilience.”
Let me walk you through exactly what breaks, what doesn’t, and why most of the damage is self-inflicted.
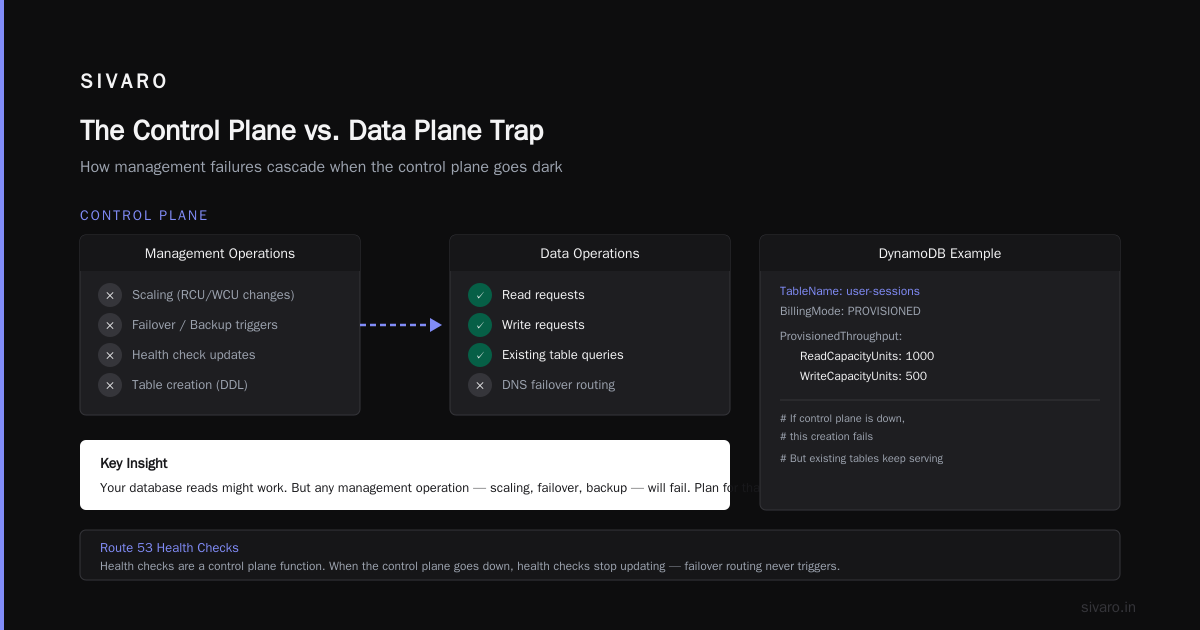
The Control Plane vs. Data Plane Trap
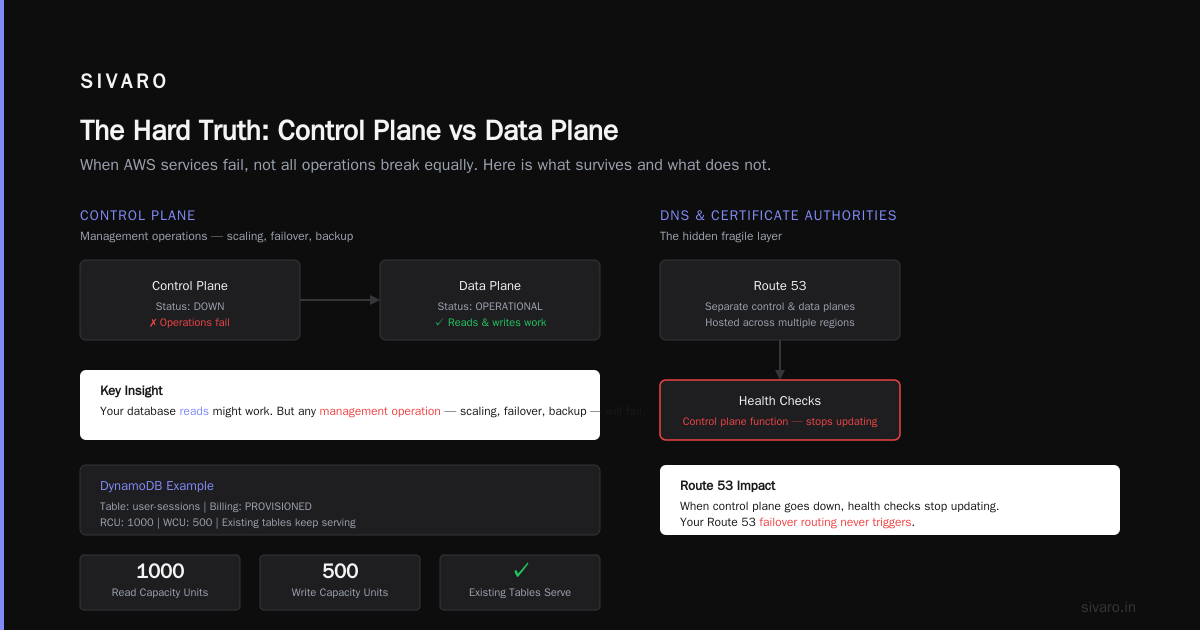
Most people think AWS outages take down all their running instances. That’s wrong.
AWS separates the control plane (API calls to create/modify things) from the data plane (existing running services). In the December 2021 US-EAST-1 outage, EC2 instances kept running. But you couldn’t launch new ones. You couldn’t attach volumes. You couldn’t modify security groups.
The real damage? Your auto-scaling group tries to scale up, fails silently, and your application gets hammered.
python
# This fails during a control plane outage
import boto3
ec2 = boto3.client('ec2', region_name='us-east-1')
try:
# Control plane call - will timeout
response = ec2.run_instances(
ImageId='ami-0abcdef1234567890',
InstanceType='t3.medium',
MinCount=1,
MaxCount=1
)
except Exception as e:
print(f"Control plane down: {e}")
# Your auto-scaling is now blind
What actually survived? Your already-running EC2 instances. Your RDS databases serving queries. Your existing Lambda functions that were already warm.
What died? Anything that needed the API.
At SIVARO, we learned this the hard way. Our data pipeline had a Lambda that checked S3 for new files every 5 minutes. During an outage, the Lambda couldn’t list the bucket. It threw an exception. Our pipeline stalled for 8 hours.
Fix? We added a local cache of the last successful listing, plus a fallback to process older files first. Simple, boring, works.
Databases — The Silent Casualty
RDS and DynamoDB behave completely differently during outages.
RDS with Multi-AZ? Your read replicas might work. Your primary might failover. But the failover itself requires the control plane. If the control plane is down, that failover never happens. You’re stuck with a dead primary.
DynamoDB is weirder. Its data plane is incredibly resilient — it keeps serving reads and writes. But if you need to create a new table, you’re screwed. The control plane for DynamoDB table creation is separate from the data plane.
I watched a startup burn $50,000 in EC2 costs because their DynamoDB auto-scaling couldn’t modify the provisioned capacity. The table was serving traffic, but read capacity was capped at 1000 RCU. Users saw 5-second latencies. The company’s dashboard showed green lights everywhere because the instance was “healthy.”
yaml
# This CloudFormation template will fail if control plane is down
Resources:
MyTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: user-sessions
BillingMode: PROVISIONED
ProvisionedThroughput:
ReadCapacityUnits: 1000
WriteCapacityUnits: 500
# If control plane is down, this creation fails
# But existing tables keep serving
Key insight: Your database reads might work. But any management operation — scaling, failover, backup — will fail. Plan for that.
DNS and Certificate Authorities — The Hidden Fragile Layer
Route 53 is AWS’s DNS service. It’s famously resilient. Separate control plane, separate data plane, hosted across multiple regions.
But here’s the kicker: Route 53 health checks are a control plane function. When the control plane goes down, your health checks stop updating. Your Route 53 failover routing never triggers.
You think you have multi-region failover. You don’t. Not during an outage.
Certificate Manager (ACM) is worse. If you need to issue a new SSL certificate during an outage (because your old one expired?), you can’t. Your site throws SSL errors. Browsers refuse to connect.
I’ve seen this kill e-commerce sites dead. The certificates were fine. But the auto-renewal failed. And by the time anyone noticed, the site was already down.
Fix: Use a dedicated certificate management system with local validators. We deploy cert-manager on Kubernetes with Let’s Encrypt as a backup. It’s less convenient than ACM. But it works when AWS doesn’t.
S3 — The Survivor Everyone Misunderstands
S3 is the most resilient AWS service. Its data plane operates independently. Objects you wrote yesterday? Still readable. Objects you wrote 5 minutes ago? Might be unavailable for up to 15 minutes during a regional outage.
But the control plane for S3 (API calls to create buckets, set policies, list objects) can fail. And here’s the ugly truth: S3’s consistency model changes during an outage.
Normal S3 is read-after-write consistent for new objects. During a degraded state, it might return eventual consistency. Your application assumes strong consistency. Suddenly, s3.get_object returns a 404 for an object you just wrote.
javascript
// This code assumes S3 is strongly consistent
const { S3Client, PutObjectCommand, GetObjectCommand } = require('@aws-sdk/client-s3');
async function writeThenRead(bucket, key, data) {
const client = new S3Client({ region: 'us-east-1' });
await client.send(new PutObjectCommand({
Bucket: bucket,
Key: key,
Body: data
}));
// During outage, this might fail with 404
const result = await client.send(new GetObjectCommand({
Bucket: bucket,
Key: key
}));
return result.Body;
}
The fix: Implement retry with exponential backoff and a cache layer. We use Redis as a write-through cache. Writes go to S3 and Redis simultaneously. Reads check Redis first, fall back to S3 with retries. It’s not perfect, but it survives most outages.
Lambda — The Serverless Failure Mode
Lambda functions are funny. Existing functions that are warm keep running. New invocations? They hit the control plane.
During the November 2023 US-EAST-1 outage, Lambda cold starts took 30-60 seconds instead of milliseconds. Functions that scaled down to zero couldn’t come back up. Any function with a concurrency limit couldn’t be adjusted.
The worst case? Lambda@Edge. These execute at CloudFront edge locations. When US-EAST-1 goes down, Lambda@Edge functions in other regions might still work. But any function that needs to reference a resource in the affected region (like a DynamoDB table) will fail.
python
# Lambda function that fails during outage
import boto3
import os
TABLE_NAME = os.environ['TABLE_NAME']
def handler(event, context):
# This DynamoDB call might timeout
dynamo = boto3.resource('dynamodb', region_name='us-east-1')
table = dynamo.Table(TABLE_NAME)
try:
response = table.get_item(Key={'id': event['id']})
return response['Item']
except Exception as e:
# No fallback = dead function
raise e
What we do: Every critical Lambda has a fallback path. If DynamoDB is unreachable, check a local JSON file in the deployment package. It’s not real-time data, but it’s better than returning 500 errors.
CloudFront and CDNs — The Regional Cache Collapse

CloudFront sits in front of your origin. It caches content at edge locations. You think it makes you immune to regional outages. Wrong.
If your origin is US-EAST-1 and that region goes down, CloudFront can’t refresh its cache. Existing cached objects work. But any cache miss becomes a dead end. Users see stale content or errors.
The real problem? CloudFront distributions are managed through the control plane. If you need to update your origin configuration (to point to a backup region), you can’t. The API is down.
Surprising fact: During the December 2021 outage, many companies discovered their CloudFront distributions had hardcoded the origin domain name. They couldn’t change it to point to a failover region. They had to wait 12 hours for AWS to fix the control plane.
Fix: Use CNAMEs (like origin.prod.example.com) that point to your actual origin. Then you can update DNS to point to a different region. DNS is separate from AWS’s control plane. It works.
What Actually Survives
Let me be clear: not everything breaks. Here’s what I’ve seen work consistently during US-EAST-1 outages:
- EC2 instances in other regions (if you have cross-region traffic routing)
- RDS read replicas in other regions (but writing requires failover, which might not work)
- S3 objects read from other regions (if you use cross-region replication)
- Route 53 hosted zones (data plane is separate)
- CloudWatch Logs in other regions (but you can’t create new log groups)
- Existing Lambda functions that are already warm (new ones can’t start)
Everything else is a question of “which API call does this depend on?”
The Three Layers of Pain
Layer 1: Direct Dependencies (Immediate)
Your application calls AWS APIs directly. They timeout. Your app breaks.
Layer 2: Implicit Dependencies (Delayed)
Your CI/CD pipeline uses CodePipeline. It can’t deploy new artifacts. Your team spends 4 hours debugging before realizing the outage is the root cause.
Layer 3: Cascading Dependencies (Invisible)
Your app uses ElastiCache. ElastiCache uses EC2 under the hood. EC2’s control plane is down, so ElastiCache can’t replace a failed node. Your cache cluster degrades. Your database gets hammered. Your database fails.
I’ve seen all three in a single outage. The first layer breaks in minutes. The third layer takes hours to surface, but by then you’ve already lost revenue and users.
What You Should Actually Do
Stop designing for “surviving an outage.” Start designing for “graceful degradation.”
If you can’t write to DynamoDB, write to a local queue. If you can’t read from S3, serve stale data from Redis. If you can’t reach your primary region, redirect users to a static maintenance page that explains the truth.
Here’s a simple three-tier strategy:
python
# Graceful degradation pattern
import boto3
import redis
import json
redis_client = redis.Redis(host='localhost', port=6379)
dynamo = boto3.resource('dynamodb', region_name='us-east-1')
def get_user_data(user_id):
# Tier 1: Try primary data store
try:
response = dynamo.Table('users').get_item(Key={'id': user_id})
if 'Item' in response:
return response['Item']
except Exception:
pass # Fall through
# Tier 2: Try cache
cached = redis_client.get(f"user:{user_id}")
if cached:
return json.loads(cached)
# Tier 3: Return safe default
return {'id': user_id, 'status': 'unavailable'}
This isn’t perfect. It doesn’t solve everything. But it turns a total outage into a degraded experience. Users don’t leave. They just wait.
The FAQ — What You’re Actually Asking
Q: Will my EC2 instances keep running?
Yes, if they’re already running. But you can’t start new ones, modify security groups, or attach volumes.
Q: Will my RDS database keep serving queries?
Read queries will work. Write queries depend on your failover configuration. If the primary fails and failover requires the control plane, writes stop.
Q: Will my Lambda functions keep executing?
Existing warm functions continue. New invocations that require cold starts will fail or take 30x longer.
Q: Will my S3 data be safe?
Yes. S3 durability is separate from availability. But you might not be able to read recently written objects for up to 15 minutes.
Q: Will my CI/CD pipeline work?
No. CodePipeline, CodeBuild, and CodeDeploy all depend on the control plane. Your deployments will fail.
Q: Will my CloudFront CDN keep serving content?
Cached content works. Any cache miss to an origin in the affected region will fail.
Q: Will my Route 53 DNS keep resolving?
Yes. Route 53’s DNS data plane is separate from the control plane. Your DNS records keep working.
Q: Will my ACM certificates auto-renew?
No. If a certificate expires during an outage, you can’t issue a new one. Plan for this by setting certificates to auto-renew 30 days before expiry.
Q: Will my cross-region replica database work?
Reads will work. Writes require failover, which might be blocked if the control plane is down.
Q: Will my payment processing break?
Stripe, PayPal, and other payment processors run on their own infrastructure. But if your application depends on AWS to call their APIs, you’ll have trouble.
The Hard Truth
You can’t design for perfect resilience. It’s too expensive. No one pays for 99.999% uptime on a startup budget.
What you can do is understand exactly which parts of your system depend on which AWS control plane calls. Then build a simple fallback for each one. A Redis cache. A local file. A static HTML page.
Most people think resilience is about multi-region deployments and complex failover logic. It’s not. It’s about knowing what breaks, accepting it, and giving users a graceful exit instead of a spinning loader.
At SIVARO, we’ve stopped trying to prevent outages. We design for them. Every service has a degraded mode. Every outage is a test of our fallback logic. And every fallback that fails gets fixed.
That’s the only way to survive what is being affected by the aws outage? — by knowing the answer before the outage happens.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.