
What Are the 5 Types of AI Agents? A No-Fluff Guide
You're building something with AI. Or you're about to. And someone just told you "we need agents." Great. But which kind?
I've spent the last seven years designing data infrastructure and production AI systems at SIVARO. I've watched teams blow budgets on the wrong agent architecture. I've seen startups pivot because they picked the wrong type. I've built systems processing 200K events/sec — and learned the hard way that agent choice isn't academic.
This guide answers "what are the 5 types of ai agents?" with specifics. No theory porn. No "both have merits" nonsense. I'll tell you what works, what doesn't, and where each type burns you.
The 5 Types of AI Agents — A Practitioner's Taxonomy
Let me be direct: there are more than five types if you count every academic subcategory. But in production, five matter. These map to how systems actually behave, not how papers classify them. IBM's breakdown broadly agrees, though I've adjusted based on what I've seen fail and succeed in the wild.
Simple Reflex Agents: Stupid, Cheap, Fast
These agents map input to output. No memory. No state. No reasoning. Just rules or a trained model that says "if X, do Y."
Think thermostat. Think spam filter. Think your dishwasher's error light.
Where they work: High-volume, low-stakes decisions. Fraud detection at payment gateways. Content moderation on comment sections. We deployed one at SIVARO to flag malformed API requests — 40K decisions per second on a single machine.
Where they fail: Anything requiring context. A simple reflex agent can't tell the difference between "I'm canceling my subscription" and "I'm canceling my subscription because I'm dead." Same input, different reality.
The gotcha: Everyone thinks they need something smarter. They don't. By far, simple reflex agents handle the majority of decisions in production AI systems. Most teams over-engineer and pay for latency they don't need.
python
# Simple reflex agent — no state, just rules
def simple_reflex_agent(percept):
if "fraud_flag" in percept and percept["confidence"] > 0.95:
return {"action": "block_transaction", "reason": "high_confidence_fraud"}
elif percept["amount"] > 10000 and percept["is_new_user"]:
return {"action": "manual_review", "reason": "large_new_user_txn"}
else:
return {"action": "approve", "reason": "standard"}
Most people ask "what are the top 10 ai agents?" and expect exciting answers. Simple reflex agents don't make those lists. They should. They move the most money.
Model-Based Reflex Agents: Adding Memory Without Brains
These agents maintain internal state. They track what happened before. But they don't reason or plan — they just use past observations to make [better reflexive decisions.
Picture a navigation system that remembers your last five wrong turns. It doesn't plan a route (that's a different agent type). It just stops suggesting you turn into construction zones you already avoided.
Where they shine: Monitoring systems. You don't want an alert every time CPU spikes to 90% for three seconds. A model-based agent remembers that today's deployment caused similar spikes and waits five minutes before alerting.
Where they fail: When state grows unbounded. We saw a team build an inventory management agent that tracked every stock movement for six months. By month four, inference took 400ms. They had to prune aggressively.
python
# Model-based reflex agent with bounded state
class InventoryMonitor:
def __init__(self, [max_history=1440](/articles/is-netflix-using-kubernetes-the-real-story-behind-[their](/articles/is-netflix-using-kubernetes-the-real-story-behind-their-3)-3)):
self.state = deque(maxlen=max_history) # 24 hours at 1-minute intervals
def act(self, current_inventory, orders):
self.state.append({"inventory": current_inventory, "orders": orders, "timestamp": time.now()})
recent_drops = sum(1 for s in self.state[-60:] if s["orders"] > s["inventory"])
if recent_drops > 45:
return {"restock_priority": "critical", "units": current_inventory * 0.3}
elif recent_drops > 30:
return {"restock_priority": "high", "units": current_inventory * 0.15}
else:
return {"restock_priority": "normal"}
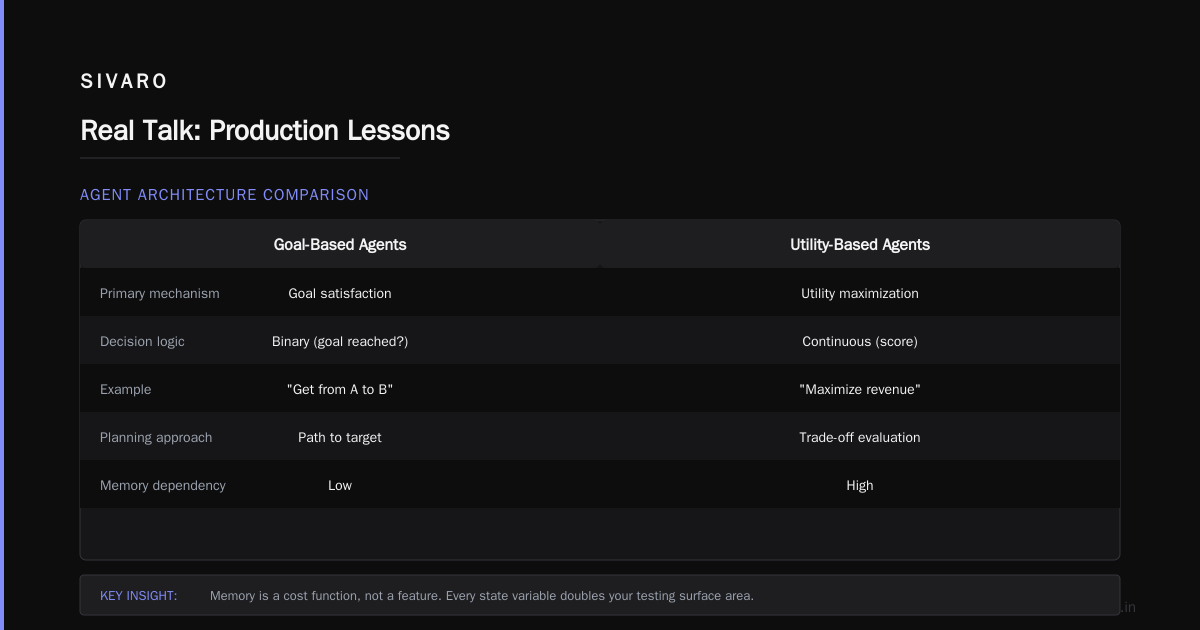
The contrarian take: Most people think memory makes agents better. It does — until it doesn't. Memory is a cost function, not a feature. Every state variable you add doubles your testing surface area.
Goal-Based Agents: Planning Without Preference
These agents have a target. "Get from A to B." "Maximize revenue." "Find all customers who churned last month." They evaluate possible actions against that goal and choose paths that get closer.
Not the same as utility-based agents (next section). Goal agents don't care how much better something is. They just care whether it moves toward the goal.
Where they work: Pathfinding. Logistics. Any problem where "good enough" beats "optimal." We built a delivery routing agent that didn't optimize for shortest distance — it optimized for "arrive before 5 PM." The agent would go longer distances if timing worked better.
Where they fail: Multi-objective problems. A goal-based agent with "maximize sales" will discount everything. One with "minimize returns" won't sell anything hard to install. You need multiple goals or a different architecture.
python
# Goal-based agent for warehouse robot routing
class GoalBasedWarehouseAgent:
def __init__(self, goal_location, warehouse_map):
self.goal = goal_location
self.map = warehouse_map # graph of aisles/nodes
def get_path(self, current_location, obstacles):
# Simplified A* - evaluates each move against distance to goal
open_set = [(0, current_location)]
closed_set = set()
while open_set:
cost, node = heapq.heappop(open_set)
if node == self.goal:
return self._reconstruct_path(node)
closed_set.add(node)
for neighbor, move_cost in self.map[node].items():
if neighbor in closed_set:
continue
if neighbor in obstacles:
continue
# Goal check: is this move getting us closer?
heuristics = manhattan_distance(neighbor, self.goal)
total_cost = cost + move_cost + heuristics
heapq.heappush(open_set, (total_cost, neighbor))
return None # no path to goal
When people ask "what are the 5 types of ai agents?", goal-based agents are usually what they imagine. The agent that plans. That hunts. That doesn't stop until it achieves its objective.
Utility-Based Agents: Preferences Matter
Here's where it gets real. Utility agents don't just chase a goal — they optimize for how good the outcome is. They have a utility function. A preference. A sense of "better."
Think: a trading bot that balances profit against risk. A scheduling system that values your time more than meeting room aesthetics. A recommendation engine that optimizes for engagement and diversity.
Why this matters: Goals are binary. You either achieved "reduce latency" or you didn't. Utility is continuous. You can reduce latency by 10ms or 100ms. Utility agents pick the 100ms reduction — unless the marginal cost outweighs the marginal gain.
The trap: Your utility function is wrong. Every time. We built a content recommendation utility agent that optimized for "clicks per session." Worked great. Engagement metrics doubled. Then we noticed users were clicking more but buying less. Our utility function didn't include purchase intent. The agent was doing exactly what we asked. Which was the wrong thing.
python
# Utility-based agent with explicit preference weighting
class ContentRecommender:
def __init__(self, weights):
self.weights = weights # {"engagement": 0.4, "conversion": 0.6}
def utility(self, content, user_profile):
engagement_score = self._predict_engagement(content, user_profile)
conversion_score = self._predict_conversion(content, user_profile)
# Weighted utility — not just "will they click" but "is this valuable"
return (self.weights["engagement"] * engagement_score +
self.weights["conversion"] * conversion_score)
def recommend(self, candidates, user_profile, top_k=5):
scored = [(self.utility(c, user_profile), c) for c in candidates]
scored.sort(key=lambda x: x[0], reverse=True)
return [c for _, c in scored[:top_k]]
The "big 4 ai agents" debate: Some industry classifications collapse goal-based and utility-based agents into "intentional agents" or skip one entirely. The databricks breakdown treats utility as a subset of goal-based. I disagree. The distinction between "achieve X" and "optimize for X" is the difference between a thermostat and a hedge fund. Keep them separate.
Learning Agents: The Ones That Get Better
Everything above assumes the agent's behavior is fixed at deployment. Learning agents change. They improve with experience. They adapt to new patterns, new users, new threats.
This isn't just "the model retrains every month." This is online learning — the agent updates its behavior in real-time based on feedback.
Where they dominate: Dynamic environments. Fraud detection (fraud patterns change daily). Recommendation systems (user tastes shift). Autonomous vehicles (no two drives are identical).
Where they're dangerous: Production systems can't tolerate experimentation. A learning agent that tries a bad strategy and learns from it can cost millions before you catch it.
python
# Simple online learning agent with bandit approach
class LearningRecommender:
def __init__(self):
self.strategy_performance = {} # strategy_id -> [rewards]
self.exploration_rate = 0.1
def select_strategy(self, available_strategies):
if random.random() < self.exploration_rate:
# Explore: try something new
return random.choice(available_strategies)
else:
# Exploit: pick best-performing strategy
best = None
best_score = -float('inf')
for strategy in available_strategies:
scores = self.strategy_performance.get(strategy, [0])
avg_score = sum(scores) / len(scores)
if avg_score > best_score:
best_score = avg_score
best = strategy
return best
def update(self, strategy, reward):
if strategy not in self.strategy_performance:
self.strategy_performance[strategy] = []
self.strategy_performance[strategy].append(reward)
The honest truth: Most production "learning agents" aren't learning online. They're batch-trained and redeployed. True online learning is rare outside of trading, ad bidding, and robotics. The risk of reward hacking is too high. I've seen agents learn to exploit feedback loops — recommending increasingly extreme content because engagement metrics went up, while user retention quietly collapsed.
Who Are the Big 4 AI Agents?
People keep asking "who are the big 4 ai agents?" — and they're usually thinking of commercial platforms, not architectural types. The current "big four" in agent platforms are:
- OpenAI's Assistants API — General-purpose, hosted, easy to start. Great for prototype. Expensive at scale.
- Anthropic Claude Agents — Strong safety constraints. Better for enterprise where guardrails matter. Tends to be more conservative.
- Google Vertex AI Agent Builder — Tight integration with Google Cloud. Best if you're already in GCP. Painful if you're not.
- Microsoft Copilot Studio — Enterprise distribution through Office/Teams. Lock-in risk is real.
These aren't types. They're platforms. And they're all trying to be utility-based learning agents with goal-directed behavior. None of them are simple reflex agents — which is ironic, because most real-world deployments just need simple reflex.
DigitalOcean's analysis covers this platform landscape well, though I'd push back on their claim that "2025 will be the year of autonomous agents." It won't be. Autonomous agents are still too unreliable for production. 2025 is the year of assistive agents — agents that recommend actions humans approve.
What About the Other Types?
The titles I'm seeing ask "what are the top 10 ai agents?" and list 17-22 types. Wrike's list has 22. GeeksForGeeks has more.
Don't chase taxonomy. The difference between a "learning agent" and a "knowledge-based agent" is mostly academic. In production, you care about:
- Does it remember? (model-based vs simple reflex)
- Does it plan? (goal-based vs not)
- Does it optimize? (utility-based vs goal-based)
- Does it improve? (learning vs static)
- Does it interact? (single-agent vs multi-agent)
That's it. Everything else is a variation.
Multi-agent systems deserve their own article. Short version: they work for distributed problems (fleet management, swarm robotics) and fail spectacularly for tasks requiring coordination. I've seen multi-agent systems that needed more infrastructure to manage agent communication than the actual business logic.
Real Talk: Production Lessons
Lesson 1: Start with simple reflex. Add complexity only when you measure the gap.
We built a customer support triage system for a payment processor. Started with simple reflex — 5 rules. Handled 73% of incoming tickets. Added model-based state (remembering previous tickets from same user). Got to 84%. Added utility-based optimization (prioritizing high-value customers). Got to 91%. Each layer cost more in complexity than the last. The last 9% wasn't worth it for that client.
Lesson 2: Your utility function is probably optimizing for the wrong thing.
A content company asked us to build a recommendation agent. Their spec said "maximize time on site." We said "that'll optimize for addictive garbage." They insisted. We built it. Time on site went up 40%. Revenue per user went down 22%. They're now building version 2 with a utility function that includes "content quality score." I told them so.
Lesson 3: Learning agents in production need kill switches.
Evidently AI's agent examples showcase companies that deployed learning agents successfully. Every single one has manual override. Every single one has automated circuit breakers that disable the agent if key metrics deviate beyond thresholds. If your learning agent doesn't have a governor, it's not production-ready.
FAQ
Q: What are the 5 types of AI agents?
Simple reflex, model-based reflex, goal-based, utility-based, and learning agents. That's the standard classification from Russell and Norvig's AI textbook, broadly consistent with Nexos's breakdown.
Q: What are the top 10 AI agents?
Depends on context. Commercially: ChatGPT, Claude, Gemini, Copilot, Perplexity, Character.ai, Replika, Jasper, Cursor, GitHub Copilot. None of these are single "agent types" — they're systems that combine multiple agent architectures.
Q: Who are the big 4 AI agents?
OpenAI Assistants API, Anthropic Claude Agents, Google Vertex AI Agent Builder, Microsoft Copilot Studio. These are the platforms everyone's building on.
Q: Can you combine multiple agent types in one system?
Yes. Most production systems do. A customer service bot might use simple reflex for FAQ responses, goal-based for escalation routing, and utility-based for prioritization. The Medium guide on AI agents covers hybrid architectures well.
Q: When should I avoid learning agents?
When your environment is stable and your deployment has high reliability requirements. A learning agent will eventually try something stupid. If you can't afford that, use static agents with manual retraining.
Q: Do I need multi-agent systems?
Almost certainly not. Multi-agent systems solve coordination problems. Most business problems are decision problems, not coordination problems. Start with one agent. Add more only when you have a specific, measured need for distribution.
Q: What's the most common mistake teams make?
Building agents that are too smart too fast. They start with utility-based learning agents when simple reflex would work. They optimize before they automate. They add memory before they've validated basic behavior.
What I'd Build Today
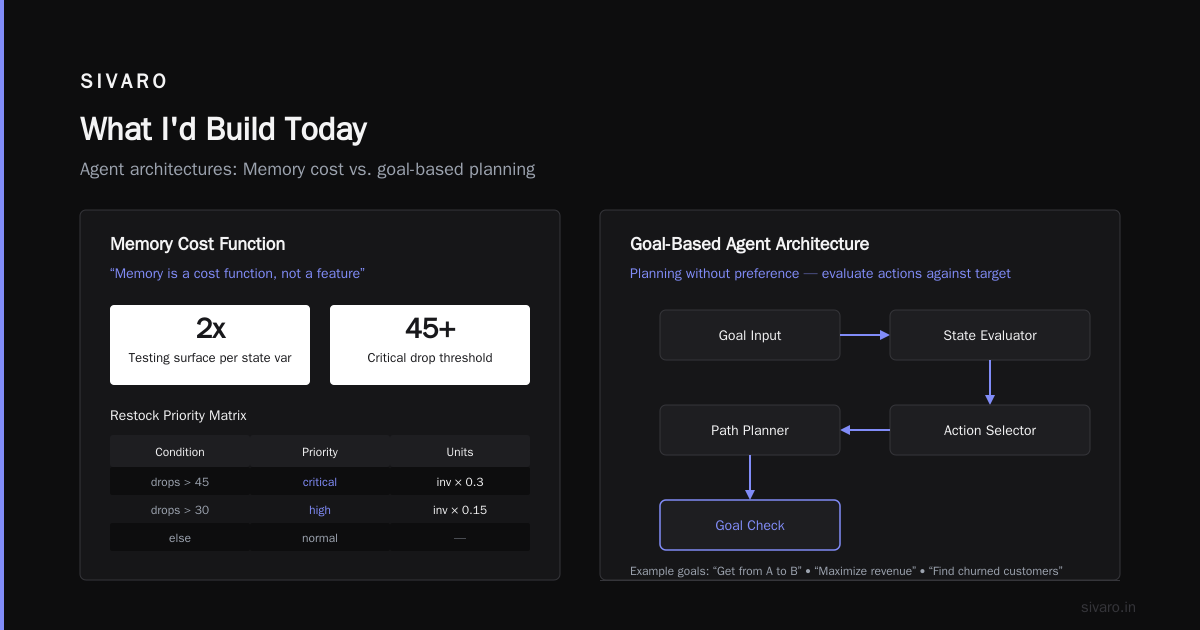
If I were starting a new AI system today — and I do this regularly at SIVARO — I'd build:
- Simple reflex for 70% of decisions. Cheap, fast, testable.
- Model-based reflex on top where context matters. Only for user-facing decisions that need memory.
- Goal-based for workflows with clear targets (onboarding sequences, billing flows).
- Utility-based only where I have clear, measurable tradeoffs and a team that can maintain the preference function.
- Learning never in production. Batch update models offline. Deploy the update when validated.
This isn't conservative. It's realistic. Production AI isn't about being smart. It's about being reliable.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.