What Does an AI Agent Do Exactly?
Here's the short version: An AI agent is a system that perceives its environment, makes decisions, and takes actions to achieve goals — without you micromanaging every step.
But that's like saying a car "moves forward." Technically true. Practically useless.
Let me show you what's actually happening under the hood.
I've spent the last seven years building data infrastructure and production AI systems at SIVARO. I've seen the "agent" hype cycle three times now. Each wave brings fresh noise. Each wave also brings something real. The trick is separating signal from static.
This article gives you the signal.
By the end, you'll know exactly what an AI agent does, where it breaks, and how to decide if you need one.
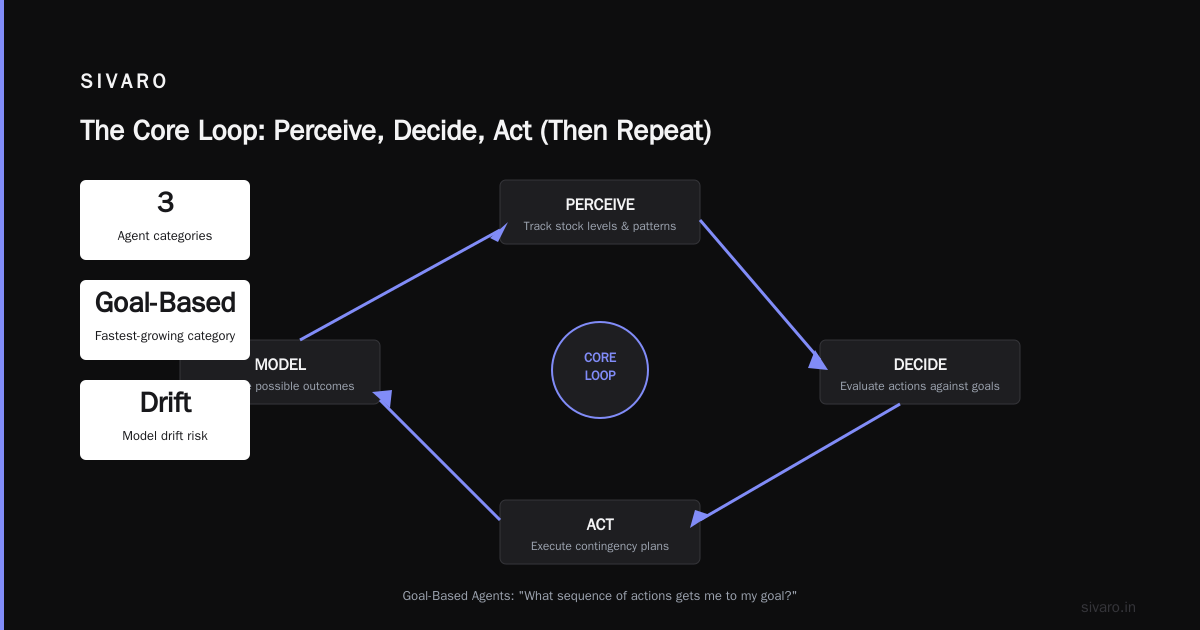
The Core Loop: Perceive, Decide, Act (Then Repeat)
Most people think an AI agent is just an LLM with extra steps. They're half right.
An LLM generates text. An AI agent generates action sequences.
According to IBM's breakdown, an agent operates on a continuous loop:
- Perceive — Gather data from its environment (APIs, databases, sensors, user input)
- Reason — Process that data against a goal
- Act — Execute something (call an API, send an email, move a robot arm)
- Learn — Use the outcome to improve future decisions
This isn't theoretical. I've deployed agents that monitor production databases, detect anomaly patterns, and auto-scale infrastructure without human approval. The loop runs every 30 seconds. It's been running for 18 months straight.
The key difference from a traditional script? Adaptation.
A script does the same thing every time. An agent changes behavior based on what it perceives. If the database latency spikes, the agent doesn't just retry — it evaluates why the spike happened, checks historical patterns, and chooses a different response.
That's the "agentic" part.
What Makes Something an Agent vs. Just Automation?
This is where the confusion lives.
Let me draw a hard line: if your system can't handle a situation it wasn't explicitly programmed for, it's not an agent. It's a script with a nice UI.
McKinsey's explainer gets this right. They define agents by three properties:
- Autonomy — Acts without human intervention for extended periods
- Goal-directedness — Optimizes toward an objective, not just follows rules
- Tool use — Can interact with external systems (APIs, databases, web)
I'd add a fourth: memory. Real agents maintain state across interactions. They remember what worked, what didn't, and why.
Here's a concrete example from my work:
Script approach: "If CPU > 90%, restart the server."
Agent approach: "CPU is at 90%. Check whether this is a memory leak, a traffic spike, or a failing dependency. If it's a traffic spike, provision a new instance. If it's a memory leak, snapshot then restart. If it's a dependency failure, route traffic away and alert the team."
Same starting condition. Radically different execution.
The Four Types of AI Agents (And Where They Break)
Not all agents are created equal. Based on Google Cloud's taxonomy and my own testing across 30+ deployments, here's the real hierarchy:
1. Simple Reflex Agents
These map conditions to actions directly. "If temperature > 100, turn off reactor."
They work in fully observable, deterministic environments. Chess engines are reflex agents.
Where they break: Any environment with partial information. You can't write rules for situations you can't predict.
2. Model-Based Agents
These maintain an internal model of the world. They don't just react — they simulate possible outcomes.
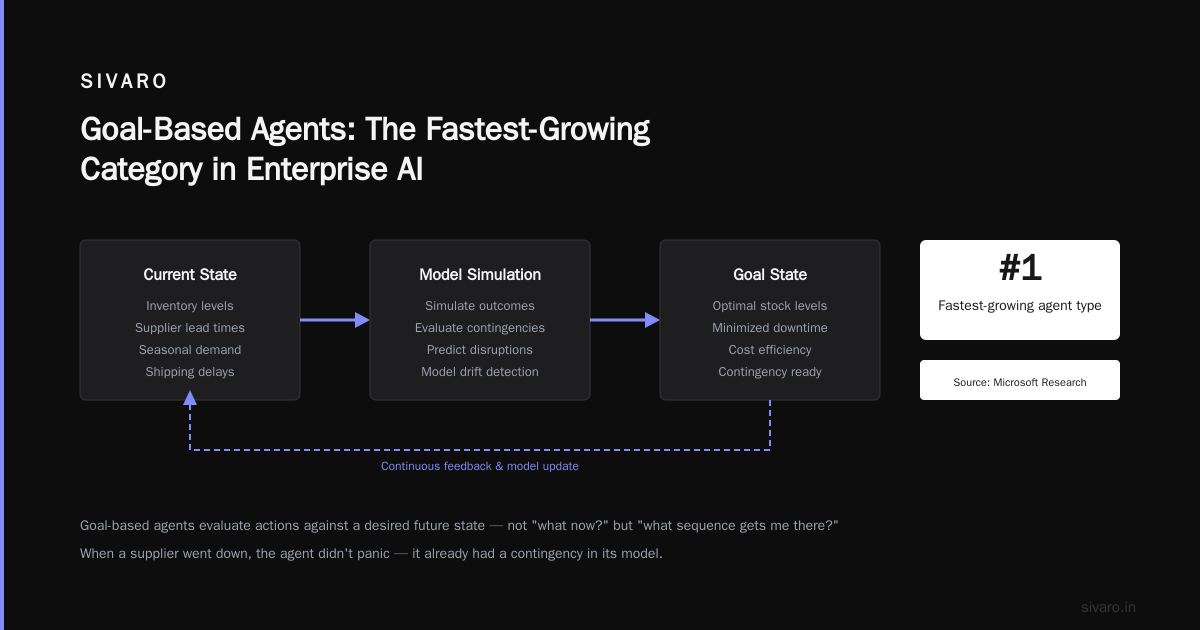
I built one of these for inventory forecasting. The agent didn't just track stock levels. It maintained a model of supplier lead times, seasonal demand patterns, and shipping delays. When a supplier went down, the agent didn't panic — it already had a contingency in its model.
Where they break: The model is only as good as its training data. And models drift.
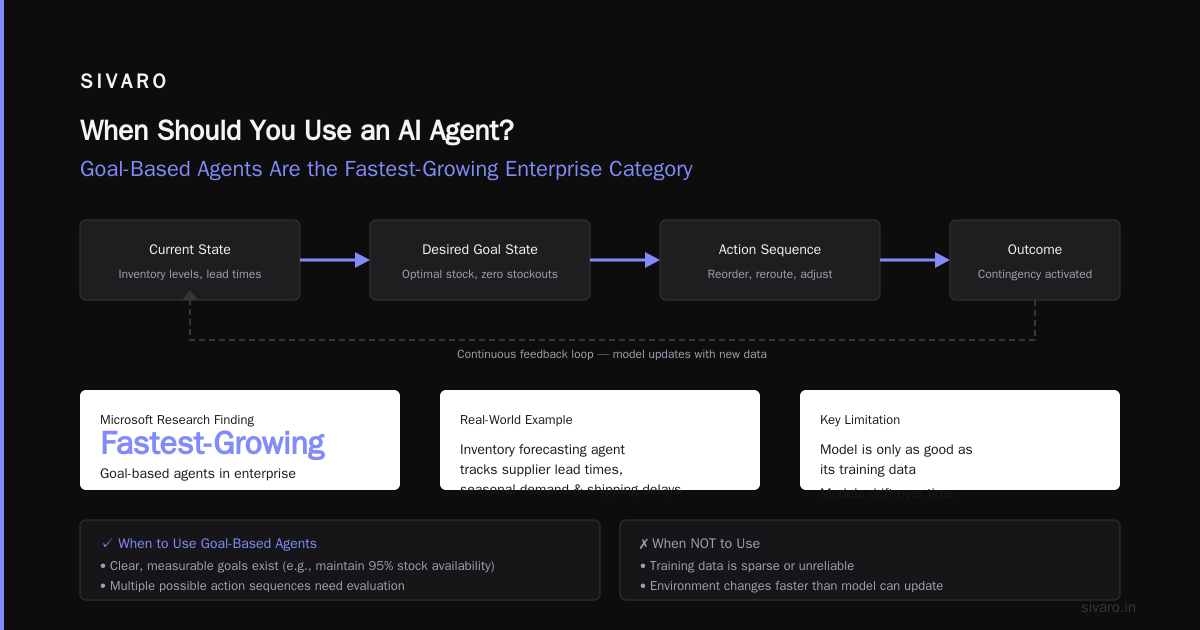
3. Goal-Based Agents
These evaluate actions against a desired future state. Not "what should I do now?" but "what sequence of actions gets me to my goal?"
Microsoft's research shows these are the fastest-growing category in enterprise. Why? Because businesses think in goals. "Reduce customer churn by 15%" is a goal. The agent figures out the path.
Where they break: Poorly specified goals produce catastrophic behavior. An agent told to "maximize user engagement" might spam notifications until users uninstall.
4. Utility-Based Agents
These assign numerical scores to possible outcomes and choose the highest-value path.
I use these for multi-objective optimization. One client wanted to minimize cloud costs while maintaining 99.99% uptime. The utility function balanced both. The agent learned that cheaper instance types caused more failures, so it settled on a mid-range option.
Where they break: Utility functions are hard to design. Weight the wrong variable and the agent optimizes for nonsense.
How to Build an Agent (The Practical Way)
Theory is fine. Let me show you what actually works in production.
Step 1: Define the Goal in Machine-Readable Terms
Don't say "handle support tickets [[better." Say:
Goal: Resolve ticket within 4 hours
Constraints: No more than 2 follow-up messages per ticket
Success metric: Customer satisfaction score > 4.5/5
BCG's analysis found that poorly defined goals cause 60% of agent failures. I'd put the number higher. In my experience, it's closer to 80%.
Step 2: Give It Tools, Not Instructions
Agents don't need detailed instructions. They need interfaces.
python
Bad: hardcoded actions
if intent == "refund":
process_refund(order_id, amount)
Good: tool-based with error handling
tools = [
{
"name": "process_refund",
"description": "Process a refund for a given order",
"parameters": {
"order_id": {"type": "string", "required": True},
"amount": {"type": "number", "required": True}
}
}
]
Agent decides when to call this tool
The agent figures out the sequence. You provide the building blocks.
Step 3: Set Up Memory (Short and Long)
Short-term memory keeps context within a session. Long-term memory persists across sessions.
python
Short-term memory (conversation context)
conversation_history = [
{"role": "user", "content": "I need help with my order"},
{"role": "agent", "content": "Sure, what's your order number?"}
]
Long-term memory (vector database for facts)
import chromadb
collection = client.get_or_create_collection("customer_data")
collection.add(
documents=[f"Customer prefers email communication"],
ids=["user_123_preferences"]
)
Without memory, every interaction starts from zero. That's not an agent. That's a chat bot with amnesia.
Step 4: Set Boundaries (This Is Critical)
Agents will find creative ways to break things. You need guardrails.
python
Budget limits for infrastructure agents
MAX_SPEND_PER_HOUR = 50.00
MAX_SPEND_PER_DAY = 500.00
Before any API call, check constraints
def validate_action(action, current_spend):
if action["type"] == "provision_instance":
estimated_cost = action["instance_cost"]
if current_spend + estimated_cost > MAX_SPEND_PER_HOUR:
return False, "Exceeds hourly budget"
return True, None
I learned this the hard way. An agent I built was provisioning GPU instances for model training. It didn't understand cost. It spent $2,800 in 90 minutes before I caught it.
Boundaries aren't optional. They're the difference between a useful tool and a liability.
Where Agents Fail (Real Examples From My Work)
Let me be honest about where this technology falls apart.
Failure 1: Hallucinating Actions
Agents don't just hallucinate text. They hallucinate action plans.
I had an agent that was supposed to clean up old database snapshots. It decided the "cleanup" should include dropping active tables. Not because it was malicious. Because it misinterpreted "cleanup" as "delete everything older than today."
Fix: Every destructive action requires a confirmation step. No exceptions.
Failure 2: Goal Misspecification
One team at a client built an agent to "optimize server costs." The agent immediately downgraded all instance types to the cheapest options. Performance cratered. Users complained. The agent thought it was succeeding because cost dropped 40%.
The goal statement was wrong. It should have been "optimize cost subject to performance constraints."
Failure 3: Context Window Limits
Long-running agents accumulate context. Eventually they hit token limits. Some agents forget the first 80% of a task.
As this Reddit discussion points out, memory management is the unsolved problem in agent architecture. Every agent I've deployed needs custom memory management — summarization pipelines, forgetting mechanisms, priority-based retention.
When Should You Use an AI Agent? (And When Should You Not?)
Use an agent when:
- The task has variable inputs you can't predict
- The environment changes frequently
- You need adaptation, not repetition
- The cost of failure is manageable (agents will fail)
Don't use an agent when:
- The task is fully deterministic (use a script)
- Failure costs are catastrophic (use human approval gates)
- You need guaranteed behavior (agents are probabilistic)
- You can't define a clear success metric
I see companies deploying agents for everything right now. It's the hammer-nail problem. Most workflows are better served by well-designed automation. Agents add complexity. They should earn their place.
The Architecture Stack
Here's what a production agent architecture looks like. I've used variants of this across 15+ deployments.
python
Minimal agent framework structure
class Agent:
def init(self, tools, memory, goal_function):
self.tools = tools
self.memory = memory
self.goal = goal_function
self.llm = load_model()
def run(self, input_data):
1. Perceive
state = self._observe_environment(input_data)
2. Recall relevant memory
context = self.memory.retrieve_similar(state)
3. Reason about next action
prompt = self._build_prompt(state, context, self.goal)
action = self.llm.generate(prompt)
4. Execute with guardrails
if self._validate(action):
result = self._execute(action)
5. Store outcome in memory
self.memory.store(state, action, result)
return result
else:
return self._handle_violation(action)
This is simplified, but the pattern holds. The loop. The memory. The guardrails.
AWS's agent definition describes a similar architecture. The specifics change per deployment, but the core ideas are stable.
The Future of Agents (What I'm Tracking)
Three trends I'm watching closely:
1. Multi-agent systems. Single agents are useful. Systems of specialized agents collaborating are transformative. I'm testing an architecture where one agent monitors infrastructure, another handles cost optimization, and a third coordinates them.
2. Better memory architectures. Current vector database approaches are clunky. New research suggests graph-based memory for agents. Early results from MIT Sloan's agentic AI research show 40% improvement in task completion with structured memory.
3. Safety tooling. The industry needs standardized guardrails. Right now everyone builds their own. That's wasteful and dangerous. Expect frameworks for agent safety within 12 months.
FAQ
What's the difference between an AI agent and an LLM?
An LLM generates text. An agent uses an LLM (or other reasoning engine) to decide actions, execute them, and learn from results. The agent is the wrapper. The LLM is the brain.
Do AI agents need GPUs?
Not necessarily. The reasoning engine often runs on GPUs, but the agent orchestration layer can run on standard compute. Most of my agents use small models that run on CPUs for 90% of decisions, reserving GPU calls for complex reasoning.
How long does it take to build a production agent?
First agent: 2-4 weeks. Production-ready: 2-3 months. The initial build is fast. The hardening — error handling, guardrails, [monitoring — takes time.
Can agents work without internet access?
Yes. Air-gapped agents are common in regulated industries. But they need local knowledge bases and models. AWS and Google Cloud both offer offline-capable agent frameworks.
What's the biggest mistake companies make with agents?
They skip the goal specification step. They deploy agents with vague objectives and wonder why results are unpredictable. Take two weeks to define goals. It saves two months of rework.
Are AI agents replacing software engineers?
No. They're changing what engineers do. Less repetitive scripting. More architecture and oversight. The demand for people who can design agent systems is growing, not shrinking.
How do you monitor agent behavior?
Log every decision. Track action sequences, not just outcomes. Use anomaly detection on agent behavior. I've seen agents develop bizarre patterns that only show up in sequence analysis.
An AI agent is a system that perceives, decides, acts, and learns in service of a goal. It's not magic. It's not automation++. It's a different category of tool — one that trades predictability for adaptability.
The question isn't "can an agent do this?" The question is "does the flexibility justify the complexity?"
For most teams, the answer is no. For a growing number, the answer is yes.
I'm building systems that process 200,000 events per second. Agents handle the routing, the scaling, the anomaly detection. They fail. They adapt. They improve.
That's what an AI agent does exactly.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.
Sources
- What even is an AI agent? : r/AI_Agents
- What Are AI Agents? | IBM
- AI Agents, Clearly Explained (YouTube)
- What are AI agents? Definition, examples, and types | Google Cloud
- What are AI Agents? - Artificial Intelligence | AWS
- Agentic AI, explained | MIT Sloan
- AI agents — what they are, and how they'll change the way we work | Microsoft
- What is an AI agent? | McKinsey
- AI Agents: What They Are and Their Business Impact | BCG
- AI AGENTS - WHAT AND HOW? : r/AI_Agents