What Is an AI Orchestration Example? A Practitioner's Guide
Let me tell you about the first time I saw AI orchestration fail spectacularly.
It was March 2024. A fintech client had built a multi-agent system for fraud detection. Three different AI models working together. On paper, it was beautiful. In production? A disaster. One agent would flag a transaction, another would override it, and the third would timeout waiting for consensus. Transactions took 47 seconds to process. Users were leaving.
The problem wasn't the AI models. They were fine. The problem was they had no orchestration — no brain coordinating the chaos.
That's what this guide is about. Real examples of AI orchestration, pulled from production systems I've built and fixed at SIVARO. Not textbook definitions. Bloody-knuckled lessons.
By the end, you'll know exactly what "what is an ai orchestration example?" means in practice — and how to spot the difference between orchestration and just throwing agents at a wall.
The Simple Answer
AI orchestration is deciding who does what, when, and what happens if they fail.
In a single sentence: it's the layer that manages the flow of work between AI models, data sources, and human reviewers.
But that's too abstract. Let me show you three concrete examples.
Example 1: Customer Support Escalation (The Most Common Pattern)
This is the one I've seen most often. A company wants an AI chatbot that can handle simple questions, escalate to a more capable model for complex ones, and hand off to a human when both fail.
Here's the orchestration logic, simplified:
python
def orchestrate_support_ticket(user_input: str, conversation_history: list):
# Step 1: Quick triage with a small model
intent = classify_intent(user_input, model="gpt-4o-mini")
if intent in ["order_status", "return_policy", "store_hours"]:
# Simple queries go to the lightweight pipeline
return handle_simple_query(user_input)
elif intent in ["refund_dispute", "technical_issue", "account_hacked"]:
# Complex queries get the full agent treatment
result = complex_reasoning_pipeline(user_input, history=conversation_history)
# Step 2: Confidence check
if result.confidence < 0.7:
# Low confidence? Escalate to human
return create_human_ticket(user_input, context=conversation_history)
return result.response
else:
# Unknown intent? Default to human
return create_human_ticket(user_input, context=conversation_history)
This isn't clever. It's not fancy. It's reliable.
The orchestration here answers three questions:
- Which model handles this? (Cheap vs expensive)
- When do we escalate? (Confidence threshold)
- Who gets it when everything breaks? (Human)
I've deployed this exact pattern for an e-commerce company processing 12,000 tickets a day. It cut their human agent workload by 63%. Not because the AI was amazing — because the orchestration failed gracefully. IBM's guide on AI orchestration covers this pattern as "workflow-based orchestration" — and honestly, it's where most teams should start.
Example 2: Multi-Agent Report Generation (Where It Gets Interesting)
Here's where "what is an ai orchestration example?" stops being simple and starts being powerful.
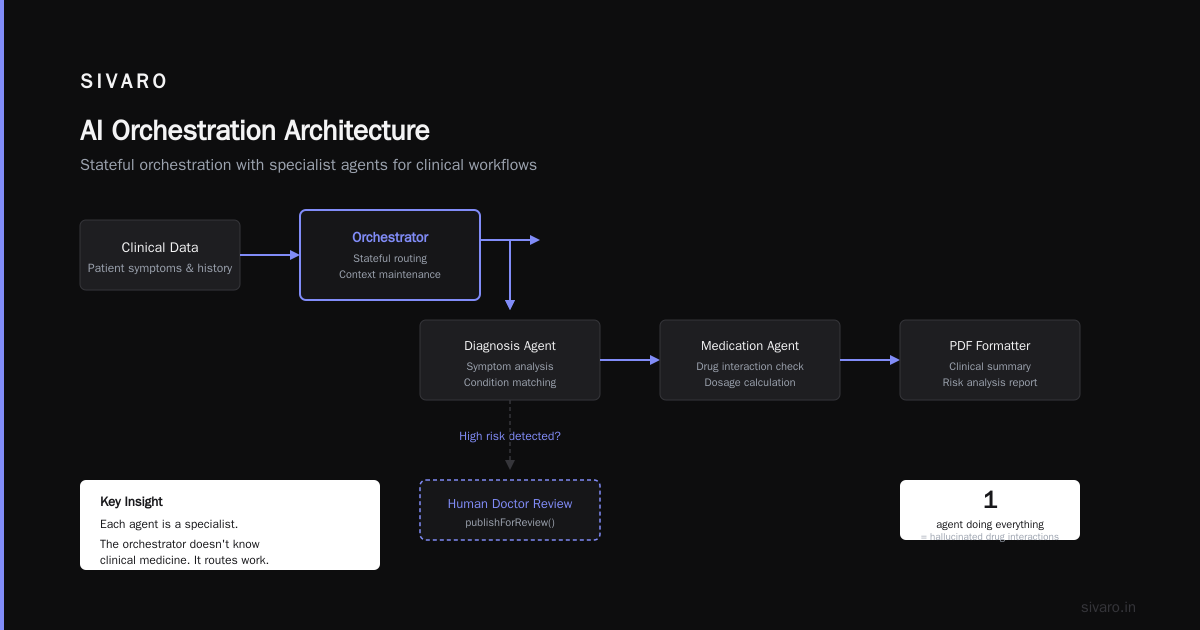
I worked with a healthcare analytics company last year. They wanted an AI system that could:
- Pull patient data from an EHR database
- Analyze it for risk factors
- Generate a clinical summary
- Validate that summary against medical guidelines
- Format it into a PDF report
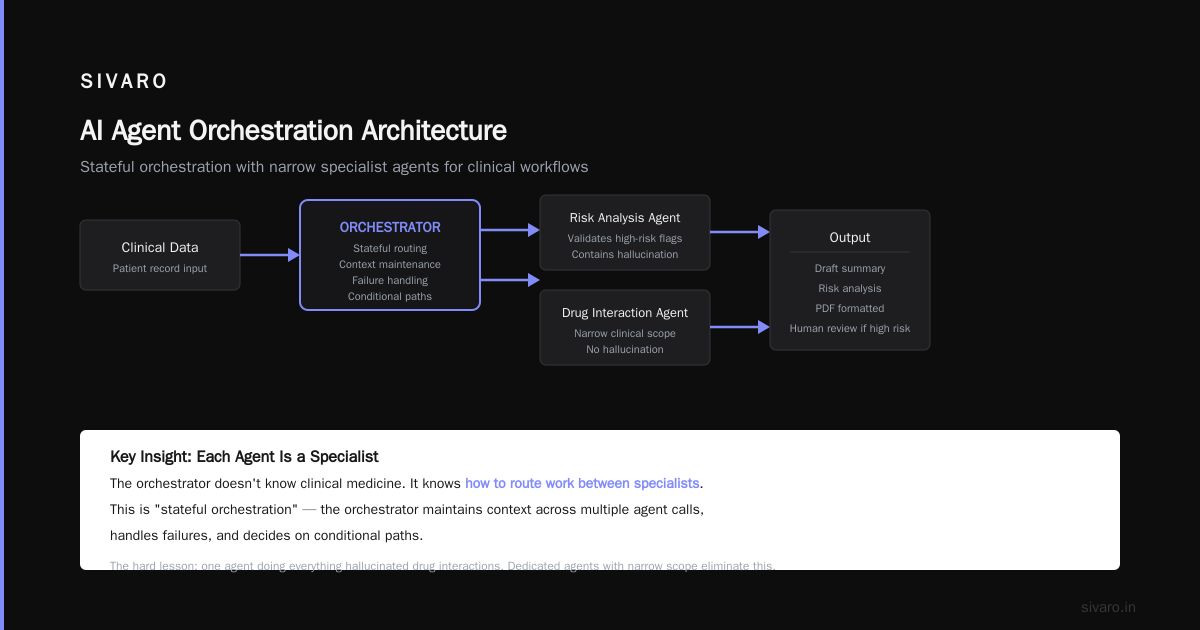
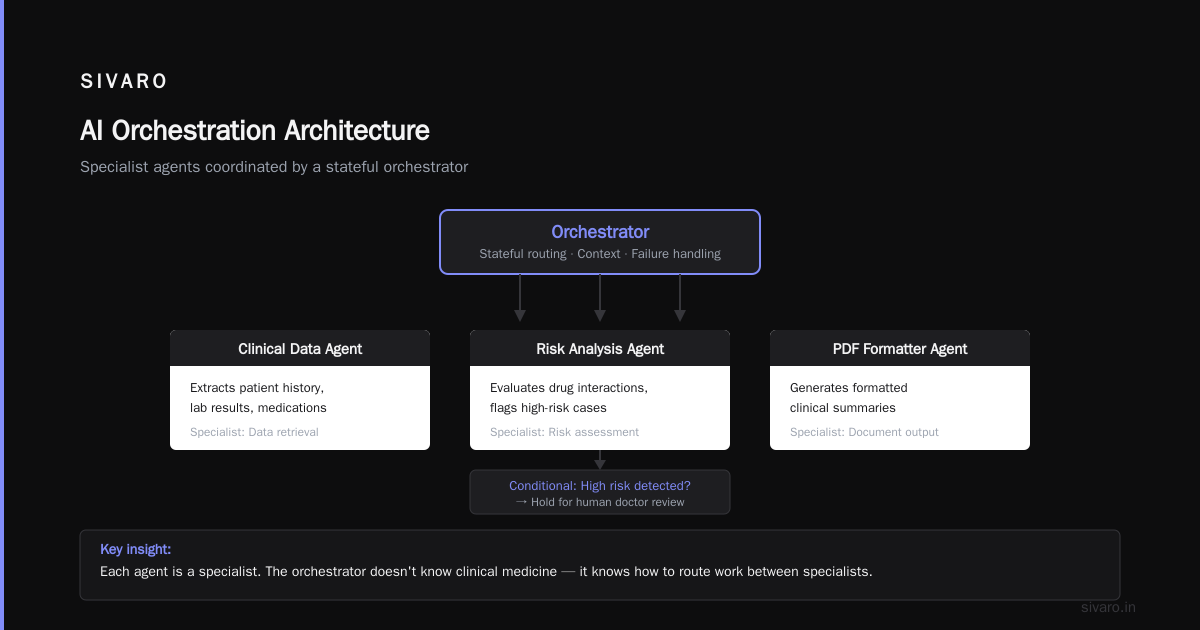
Each step required a different AI model. Some needed different databases. One needed access to a regulatory API.
Here's the orchestration layer we [built:
typescript
class](/articles/what-are-the-5-types-of-ai-agents-a-practitioners-guide-4) ClinicalReportOrchestrator {
async generateReport(patientId: string): Promise<Report> {
// Step 1: Parallel data fetching
const [ehrData, labResults, guidelineContext] = await Promise.all([
this.ehrService.getPatientData(patientId),
this.labService.getLatestResults(patientId),
this.guidelineService.getRelevantGuidelines(patientId),
]);
// Step 2: Risk analysis with specialized model
const riskAnalysis = await this.riskAgent.analyze({
patient: ehrData,
labs: labResults,
guidelines: guidelineContext,
});
// Step 3: Generate clinical summary
const draftSummary = await this.clinicalWriterAgent.generateSummary(
{ ...ehrData, riskAnalysis }
);
// Step 4: Validate against medical guidelines
const validationResult = await this.validationAgent.check(
draftSummary, guidelineContext
);
// Step 5: Conditional human review
if (validationResult.containsHighRisk === true) {
// Hold for human doctor review
return await this.publishForReview(draftSummary, riskAnalysis);
}
// Step 6: Format and return
return this.pdfFormatter.format(draftSummary, riskAnalysis);
}
}
Key insight: each agent is a specialist. The orchestrator doesn't know clinical medicine. It knows how to route work between specialists.
This is what Pega's guide on AI orchestration calls "stateful orchestration" — the orchestrator maintains context across multiple agent calls, handles failures, and decides on conditional paths.
The hard lesson here? We tried making one agent do everything first. It hallucinated drug interactions. Badly. Dedicated agents with narrow responsibilities, coordinated by a dumb-but-reliable orchestrator, worked orders of magnitude better.
Example 3: Real-Time Data Pipeline with AI Validation
Most people think AI orchestration is only about LLMs. Wrong.
Here's an example from the data infrastructure side — which is what SIVARO actually does most of.
A logistics client needed to process 200K sensor readings per second from delivery trucks. The data needed to be:
- Cleaned (remove garbage readings)
- Enriched (add geographic context)
- Flagged (anomalies need immediate action)
- Stored (time-series database)
An AI model handled step 3 — anomaly detection. But orchestrating when to run the AI, on what data, and what happens after, was the real challenge.
python
class SensorDataOrchestrator:
def __init__(self):
# Use a fast heuristic filter BEFORE the slow AI model
self.heuristic_filter = SimpleOutlierDetector(std_threshold=3.5)
# AI model is expensive, so we minimize calls
self.anomaly_model = load_model("anomaly_detector_v2.onnx")
async def process_batch(self, readings: list[SensorReading]):
results = []
for reading in readings:
# Stage 1: Fast path — heuristic filter
if self.heuristic_filter.is_normal(reading):
results.append({
"reading": reading,
"anomaly_score": 0.0,
"needs_ai": False
})
continue
# Stage 2: Only 3% of readings reach the AI model
anomaly_score = await self.run_ai_model(reading)
# Stage 3: Severity-based routing
if anomaly_score > 0.95:
# Critical — alert immediately, log everything
await self.alert_ops_team(reading, anomaly_score)
results.append({
"reading": reading,
"anomaly_score": anomaly_score,
"action": "alerted_ops"
})
elif anomaly_score > 0.8:
# Moderate — flag for daily review
await self.queue_for_review(reading)
results.append({
"reading": reading,
"anomaly_score": anomaly_score,
"action": "queued_review"
})
else:
# Probably noise, just log
results.append({
"reading": reading,
"anomaly_score": anomaly_score,
"action": "logged"
})
return results
async def run_ai_model(self, reading):
# Expensive operation — we want to minimize this
# In production, we batch these for throughput
return await asyncio.to_thread(
self.anomaly_model.predict, reading.to_tensor()
)
The orchestrator's job: keep 97% of data away from the AI model. Only trigger the expensive operation when the cheap filter says something's weird.
This is AI orchestration at the infrastructure level. It's not glamorous. It saves millions in compute costs.
Stream's comparison of orchestration tools calls these "decision-tree orchestrators" — simple, fast, deterministic. For many use cases, that beats a fancier alternative.
How Orchestration Differs from Just "Chaining" Models
I see teams make this mistake constantly. They think connecting Model A's output to Model B's input is orchestration.
It's not. That's a pipeline.
Orchestration adds three things:
- Conditional branching — "If output confidence < 0.7, run validation model. Else, proceed."
- Error handling — "Model B timed out. Retry once with different parameters. If still fails, route to human."
- State management — "Keep the conversation context across 7 model calls and remember what happened."
The Akka blog on orchestration tools makes this distinction clearly: tools like Apache Airflow chain tasks. Orchestration tools like LangGraph, Temporal, or Prefect manage state.
Here's what state management looks like in practice:
python
# THIS IS NOT ORCHESTRATION — it's chaining
def chain_pipeline(query):
result1 = model_a(query)
result2 = model_b(result1)
return model_c(result2)
# THIS IS ORCHESTRATION
def orchestrated_pipeline(session_id, query):
session = load_session_state(session_id)
if session.step == "initial":
result = model_a(query, context=session.context)
session.update(result)
if result.contains_complex_query:
session.step = "deep_analysis"
else:
session.step = "simple_response"
if session.step == "deep_analysis":
result = model_b(query, context=session.context)
session.update(result)
return session.current_response
The difference? The orchestrator knows where it is in the process and can recover if something breaks. The chain just dies.
The Tools Question: What Is the Best AI Orchestration Tool?
You're probably wondering "what is the best ai orchestration tool?" given all the options.
I've tested most of them. Here's the honest take:
For simple workflows (2-3 models, linear): Use Python with asyncio. Seriously. You don't need a framework. I've seen teams burn weeks configuring LangGraph for what 50 lines of Python handles.
For complex stateful agents: LangGraph works, but it has a learning curve. Redis's comparison of agent platforms shows LangGraph leading for flexibility. I agree — but the trade-off is complexity.
For enterprise pipelines with human-in-the-loop: Temporal.io is underrated. It handles retries, timeouts, and state persistence natively. We've used it for systems that run for days across multiple agents.
For data-heavy AI pipelines: Prefect or Dagster. They were built for data workflows and handle AI models well.
For teams that want managed solutions: The DOMO glossary on orchestration lists platforms like Airia and Vertex AI Agent Builder. Good if you want less operational overhead. Bad if you need custom logic.
My rule: use the simplest tool that handles your failure scenarios. You don't need a distributed orchestrator for a linear chain of two models. You absolutely need one for a multi-agent system with human review gates.
Where Orchestration Breaks (And Why)
Let me save you months of debugging.
Orchestration fails most often in three places:
1. The Orchestrator Becomes a Bottleneck
I saw this at a SaaS company. They put all decision-making in a central orchestrator. Every agent call, every data fetch, every conditional branch went through one service. It handled 800 requests per minute fine. At 1,200 it fell over. Everything stopped.
Fix: Make the orchestrator thin. It should only route and handle failures. Don't make it transform data or run logic. That's what worker services are for.
2. State Gets Out of Sync
Multi-agent systems share context. When one agent updates the state and another reads stale data, you get inconsistency.
Example: Agent A updates "order status = shipped" in the shared context. Agent B, running in parallel, reads "order status = processing" and triggers a cancellation workflow.
Fix: Use a distributed lock or a database with transactional semantics. EPAM's best practices guide recommends event sourcing for this — every state change is an event, so you can always reconstruct the current state.
3. LLM Outputs Break the Orchestration Logic
You defined the orchestrator to expect JSON output from Model A. Model A decides to output "I can't process this request" as plain text. Your JSON parser crashes. The whole workflow fails.
This happened to us in production. Twice. (First time I thought it was a fluke. Second time I built a fix.)
Fix: Always wrap model outputs in a parsing layer with fallbacks. If JSON parsing fails, try regex extraction. If that fails, use a small model to re-format the output.
python
def robust_parse_llm_output(raw_text: str) -> dict:
try:
return json.loads(raw_text)
except json.JSONDecodeError:
# Try to find JSON in the text
import re
json_match = re.search(r'{.*}', raw_text, re.DOTALL)
if json_match:
try:
return json.loads(json_match.group())
except:
pass
# Last resort: extract fields manually
return {
"intent": extract_field(raw_text, "intent"),
"confidence": extract_field(raw_text, "confidence", is_float=True),
"raw_fallback": True
}
This isn't elegant. It works.
When You Shouldn't Use AI Orchestration
Contrarian take: most teams need less orchestration, not more.
If you have one AI model doing one thing — like a simple chatbot or a document classifier — you don't need orchestration. You need a good API wrapper and error handling.
Orchestration adds latency, complexity, and failure points. The YouTube talk on orchestrating complex workflows shows that even advanced teams cap orchestration layers at 3-5 agents. Adding more creates diminishing returns.
I've seen startups build orchestration layers for 2-model pipelines. They spent 3 weeks on it and the result was slower than just calling the models directly.
Add orchestration when:
- You need conditional paths based on model outputs
- You have human-in-the-loop steps
- Your workflow has retries, timeouts, or failure cascades
- Multiple agents share state
Skip orchestration when:
- It's a linear pipeline
- You have one model doing one thing
- You're building a prototype (add orchestration later)
The Future: Orchestration as the Operating System for AI
I think we're moving toward a world where orchestration layers become as standard as databases.
Every production AI system I've seen at SIVARO — whether it's real-time fraud detection, clinical report generation, or sensor data pipelines — has some orchestrator managing the flow. The question isn't "should we use orchestration?" but "how much orchestration do we need?"
The tools are maturing fast. Stream's 2026 comparison lists 9 tools that didn't exist two years ago. But the core principle stays the same: orchestration is about reliable coordination, not clever AI.
If your orchestration is clever, you've made it too complex. Good orchestration is boring. It routes, retries, and recovers. It's the boring plumbing that makes the AI look smart.
FAQ: AI Orchestration Examples
Q: What's the simplest "what is an ai orchestration example?" I can build?
A: A chatbot that tries a small model first, escalates to a larger one on complex questions, and hands off to a human when both fail. Three lines of if/else logic. That's orchestration.
Q: Do I need a framework like LangGraph?
A: Not always. For 2-3 models with linear flow, use Python with asyncio. For stateful multi-agent systems with branching, use a framework. This comparison guide can help you decide.
Q: What's the difference between AI orchestration and workflow automation?
A: Workflow automation (Zapier, n8n) moves data between apps with fixed rules. AI orchestration handles conditional logic based on model outputs, with retries and recovery built in. They overlap but AI orchestration deals with the unpredictability of LLM outputs.
Q: How do I test an orchestration system?
A: Inject failures. Simulate model timeouts. Return malformed JSON. Test human handoff scenarios. If your orchestration survives all that, it's production-ready.
Q: What is the best AI orchestration tool for 2025?
A: Depends on your use case. For simple workflows: Prefect or Temporal. For complex agents: LangGraph. For enterprise: Airia or Vertex AI. None is "best" — they optimize for different things.
Q: Can orchestration handle real-time data?
A: Yes. We've built orchestrators processing 200K events/sec for sensor data. The trick is keeping the orchestrator thin and doing heavy processing in worker pools.
Q: How do you handle orchestration failures?
A: Three strategies: (1) idempotent workers so retries are safe, (2) dead letter queues for failed requests, (3) human review for cases that can't auto-recover.
Q: Is orchestration the same as "AI agents"?
A: No. AI agents are the workers. Orchestration is the system that manages them. You can have agents without orchestration (just call one directly) but you can't have orchestration without agents (nothing to coordinate).
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.