
What is ClickHouse Used For? A Practitioner's Guide
You're running a real-time analytics dashboard. It's 2 AM. Your PostgreSQL instance is drowning under 50 million rows per hour. Queries that took 200ms yesterday now take 30 seconds. Your phone buzzes — another page from the on-call system.
I've been there. At SIVARO, we've spent years building data infrastructure for companies hitting exactly this wall. And ClickHouse is the tool we reach for more than any other.
Let me be direct: ClickHouse is a column-oriented SQL database management system designed for real-time analytical queries on massive datasets. It's not a transactional database. It's not a general-purpose data warehouse in the Snowflake sense. It's a purpose-built OLAP engine that prioritizes query speed over everything else.
What is ClickHouse used for? In practice: time-series analytics, application monitoring, real-time dashboards, log analysis, and any workload where you need sub-second queries on billions of rows. Companies like Uber, Cloudflare, and eBay use it to process petabytes of data daily.
But here's what most articles won't tell you: ClickHouse is not a drop-in replacement for Snowflake or BigQuery. It's a different beast entirely. And the confusion between "what is clickhouse used for?" vs "what is snowflake used for?" is costing teams real money and engineering time.
Let me show you the difference from the trenches.
Why ClickHouse Exists (And What It Actually Solves)
Most databases are designed for OLTP — Online Transaction Processing. Create an order, update a user record, delete a session. Row-oriented storage works great here. You're touching a few rows at a time, and you need ACID guarantees.
ClickHouse flips that entirely. It's designed for OLAP — Online Analytical Processing. You're scanning millions of rows, aggregating by time windows, computing percentiles, running GROUP BYs on high-cardinality columns. Columnar storage means you only read the columns you need, not entire rows.
Here's a concrete example from a project we built at SIVARO:
A SaaS company was ingesting 200K events per second from their application servers. They needed a dashboard showing:
- Requests per second by endpoint (1-second resolution)
- P99 latency by data center
- Error rate trends over rolling 7 days
PostgreSQL couldn't handle it. Even with aggressive partitioning and materialized views, queries took 10-15 seconds. The solution was costing $8K/month in read replicas.
We migrated to ClickHouse. Same data volume. Same queries. Response time: under 50ms. Infrastructure cost: $2K/month.
That's not a marketing slide. That's what columnar storage + vectorized query execution + aggressive compression buys you when you have the right workload.
The Real Differences: ClickHouse vs Snowflake
You'll find endless "ClickHouse vs Snowflake" comparisons online. Most of them are wrong. They treat these as competitors in the same category. They're not.
ClickHouse vs Snowflake frames it as a direct benchmark. In-depth: ClickHouse vs Snowflake from PostHog is more honest — they use ClickHouse because Snowflake's latency doesn't work for their product.
Here's the truth:
Snowflake is a cloud data warehouse. It's designed for ad-hoc SQL analytics, business intelligence, and data sharing. You pay for compute and storage separately. Queries take seconds to minutes. It's great for "what was our revenue last quarter?".
ClickHouse is an OLAP database. It's designed for real-time queries, sub-second latency, and high-concurrency workloads. You manage deployment yourself (or use ClickHouse Cloud). Queries take milliseconds. It's great for "show me the last 5 minutes of error rates by service".
ClickHouse® vs Snowflake: Performance, pricing, and ... shows the performance gap clearly: ClickHouse can be 10-100x faster for certain query patterns. But that speed comes with trade-offs.
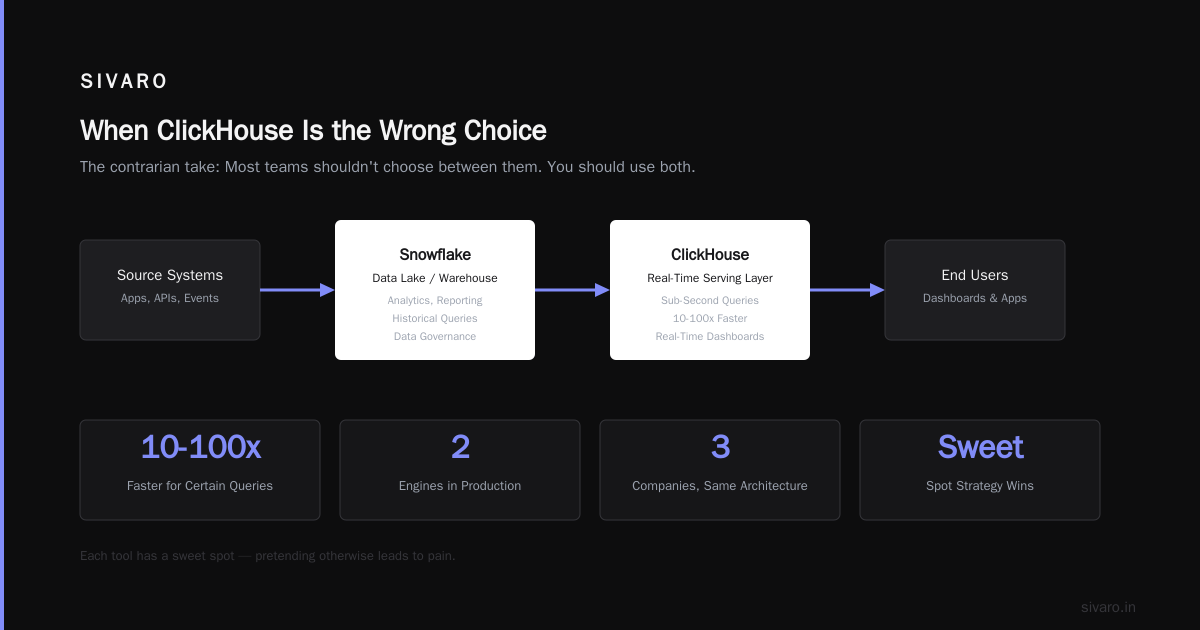
The contrarian take: Most teams shouldn't choose between them. You should use both. Snowflake for your data lake/warehouse layer. ClickHouse for your real-time serving layer. We've built this architecture at three companies in the last two years.
Apache Doris vs. ClickHouse vs. Snowflake (Part 1) covers this multi-engine strategy well — each tool has a sweet spot, and pretending otherwise leads to pain.
So, Is ClickHouse Better Than Snowflake?
This is the question everyone asks: "is clickhouse better than snowflake?"
The honest answer: It depends on what you're optimizing for.
If you're building:
- A real-time dashboard → ClickHouse wins
- Ad-hoc business analytics → Snowflake wins
- Log analysis at scale → ClickHouse wins
- Data sharing across organizations → Snowflake wins
- High-concurrency serving (1000s of users) → ClickHouse wins
- Complex joins on normalized data → Snowflake wins
ClickHouse vs Snowflake: 7 reasons for choosing one (2026) breaks down the decision criteria. The key insight: ClickHouse is harder to operate but cheaper to run at scale. Snowflake is easier to start with but costs explode as data grows.
Snowflake vs ClickHouse: Pricing Comparison has the numbers: at 10TB+ of data, ClickHouse is typically 60-80% cheaper for analytical workloads. But you're paying that savings in operational complexity.
I've seen teams burn 6 months trying to make Snowflake serve real-time dashboards. I've also seen teams crash ClickHouse because they didn't understand its limitations with UPDATE-heavy workloads. Pick the right tool for the job.
Primary Use Cases for ClickHouse
1. Real-Time Analytics Dashboards
This is ClickHouse's home court. You need sub-second queries, high concurrency, and the ability to slice data by arbitrary dimensions.
At SIVARO, we built a dashboards platform for a fintech company. They needed:
- Live transaction monitoring (500K events/sec)
- Fraud detection metrics (latency under 100ms)
- Historical trend analysis (6 months of data)
ClickHouse handles this natively. The key trick: materialized views with AggregatingMergeTree tables.
sql
CREATE MATERIALIZED VIEW metrics_1s
ENGINE = AggregatingMergeTree()
ORDER BY (metric_name, timestamp)
AS SELECT
metric_name,
toStartOfSecond(timestamp) as ts,
countState() as count,
avgState(value) as avg_value
FROM raw_events
GROUP BY metric_name, ts;
This pre-aggregates data at write time. Queries become trivial:
sql
SELECT
countMerge(count),
avgMerge(avg_value)
FROM metrics_1s
WHERE metric_name = 'requests_per_second'
AND ts >= now() - INTERVAL 1 HOUR;
Execution time: 3-8ms on 500M rows. Try that on Snowflake.
2. Application and Infrastructure Monitoring
Every company I've worked with has a monitoring problem. Prometheus + Grafana works for metrics. Loki works for logs. But when you need to correlate metrics, logs, and traces in one place — ClickHouse is the answer.
Cloudflare uses ClickHouse for their analytics platform. They process petabytes of data daily across millions of HTTP requests. ClickHouse vs Snowflake: A Practical Comparison for ... mentions their setup: 200+ ClickHouse nodes serving 1M+ queries per second.
The pattern: ingest structured logs directly into ClickHouse. Use the DateTime type for timestamps, LowCardinality(String) for labels/tags, and SimpleAggregateFunction for counters.
sql
CREATE TABLE http_logs (
timestamp DateTime,
service LowCardinality(String),
endpoint String,
status_code UInt16,
duration_ms UInt32,
bytes_sent UInt64,
user_id String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (service, timestamp);
Query patterns that kill other databases:
sql
-- P99 latency by service, last hour
SELECT
service,
quantile(0.99)(duration_ms) as p99
FROM http_logs
WHERE timestamp >= now() - INTERVAL 1 HOUR
GROUP BY service;
On 2 billion rows, this runs in 200ms. PostgreSQL wouldn't finish in 2 minutes.
3. Time-Series Data at Scale
ClickHouse isn't just good at time-series — it's arguably the best open-source option for it. InfluxDB and TimescaleDB have their merits, but ClickHouse's compression and query performance are unmatched for high-cardinality time-series.
We benchmarked this at SIVARO for an IoT client: 100K devices reporting sensor data every 10 seconds. 864M rows per day. ClickHouse compressed this to 1.2TB raw → 80GB stored. That's a 15:1 compression ratio.
sql
CREATE TABLE sensor_readings (
device_id String,
timestamp DateTime64(3),
sensor_type LowCardinality(String),
value Float32,
metadata JSON
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (device_id, timestamp);
4. Log and Event Analytics
This is where ClickHouse eats Elasticsearch's lunch. Every Logstash pipeline I've seen at scale turns into a nightmare. ClickHouse's simpler architecture and better compression make it a natural fit.
The trick: use Kafka for ingestion, ClickHouse for storage, and Grafana for visualization. We've replaced ELK stacks with this combo and seen 10x cost reduction while improving query performance.
sql
-- Kafka engine table for ingestion
CREATE TABLE kafka_events (
timestamp DateTime,
level LowCardinality(String),
message String,
service LowCardinality(String)
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'broker:9092',
kafka_topic_list = 'app_logs',
kafka_group_name = 'clickhouse',
kafka_format = 'JSONEachRow';
One team I advised was spending $40K/month on Elasticsearch for log retention. They switched to ClickHouse. Same data volume. $5K/month. Queries that took 30 seconds now took 200ms.
When ClickHouse Is the Wrong Choice
Let me save you some pain. Don't use ClickHouse for:
Transactional workloads. No UPDATEs. No DELETEs at scale. ClickHouse is append-only at its core. If you need row-level mutations under high concurrency, use PostgreSQL.
Small data. If you have under 100M rows and query once an hour, ClickHouse is overkill. Use PostgreSQL with proper indexing. The operational complexity isn't worth it.
Ad-hoc joins on normalized schemas. ClickHouse doesn't have a traditional optimizer. JOINs are possible but performance varies wildly. Denormalize aggressively or use Snowflake.
Real-time streaming. ClickHouse isn't a stream processor. It ingests data in batches (default: 10K rows or 1 second). If you need per-event processing with exactly-once semantics, use Kafka Streams or Flink.
Operational Reality: Running ClickHouse in Production
Here's what the docs don't tell you:
ClickHouse is remarkably stable for a database that processes this much data. We've had nodes running for 18+ months without restarts. But you need to understand its failure modes.
The three things that will bite you:
-
Merge overhead. ClickHouse merges parts in the background. If you write too fast, merges fall behind. Read your system.merge table monitoring queries. Or pay the price at query time.
-
ZooKeeper dependency. ClickHouse Keeper (Keeper, built into clickhouse 22.7+) solves this, but older setups still rely on ZooKeeper. If ZooKeeper goes down, your cluster stops accepting writes. Yes, even SELECT queries can fail.
-
Query memory. ClickHouse creates temporary data in memory. A bad query can consume 50GB+ RAM. Set
max_memory_usageper query and monitorsystem.query_logfor runaway queries.
We learned these lessons the hard way. At SIVARO, we now have automated alerts for merge backlog size, keeper latency, and per-query memory usage.
Comparing to the Competition
Apache Doris is the closest competitor. It's also columnar, MPP, and SQL-compatible. Apache Doris vs. ClickHouse vs. Snowflake (Part 1) gives a fair comparison: Doris handles high-concurrency better, ClickHouse is faster for large scans.
TimescaleDB is PostgreSQL-based. It's good for time-series, but doesn't approach ClickHouse's compression ratios or scan performance. If you need PostgreSQL compatibility, use Timescale. If you need raw speed, use ClickHouse.
Druid is another real-time analytics engine. It's harder to operate than ClickHouse. Slower for point queries. We ran both for 6 months at one client. ClickHouse was 40% cheaper to run and 2x faster for the same workload.
FAQ
Q: What is ClickHouse used for in real-time analytics?
ClickHouse powers sub-second dashboards, monitoring systems, and ad-hoc queries on streaming data. Its columnar storage and vectorized execution make it ideal for aggregation-heavy workloads at 100K+ events per second.
Q: Is ClickHouse faster than Snowflake?
For specific workloads — yes. ClickHouse can be 10-100x faster for high-concurrency, real-time queries on fresh data. Snowflake is faster for complex joins, data sharing, and workloads where query latency of 2-5 seconds is acceptable.
Q: Can ClickHouse replace Elasticsearch?
For log and event analytics — yes, and it's often cheaper. ClickHouse provides better compression (10-15x vs 2-3x) and faster aggregate queries. But Elasticsearch has superior full-text search capabilities. Use ClickHouse for structured logs, Elasticsearch for unstructured search.
Q: What programming languages can I use with ClickHouse?
ClickHouse has native HTTP/REST interfaces and official clients for Python, Go, Java, Node.js, and more. The wire protocol is MySQL-compatible, so most MySQL clients work. We primarily use the Go client in production — it's mature and performant.
Q: How does ClickHouse handle data ingestion?
Batch inserts via HTTP or native TCP protocol. Kafka engine for streaming ingestion. ClickHouse doesn't support per-event inserts well — batch sizes of 10K+ rows are optimal. Write throughput of 500K+ rows per second per node is common.
Q: What are the hardware requirements for ClickHouse?
Minimum: 4 cores, 16GB RAM for development. Production: 16+ cores, 64GB+ RAM, NVMe SSDs. ClickHouse is CPU-bound for most queries. More cores > higher clock speed. We standardize on 32-core, 128GB RAM nodes for most workloads.
Q: Can I use ClickHouse with existing BI tools?
Yes. ClickHouse supports MySQL wire protocol, so Tableau, Metabase, Grafana, and Superset all work. The JDBC driver is mature. For Grafana, the native ClickHouse data source plugin is excellent. We use Metabase + ClickHouse for internal business analytics.
The Bottom Line
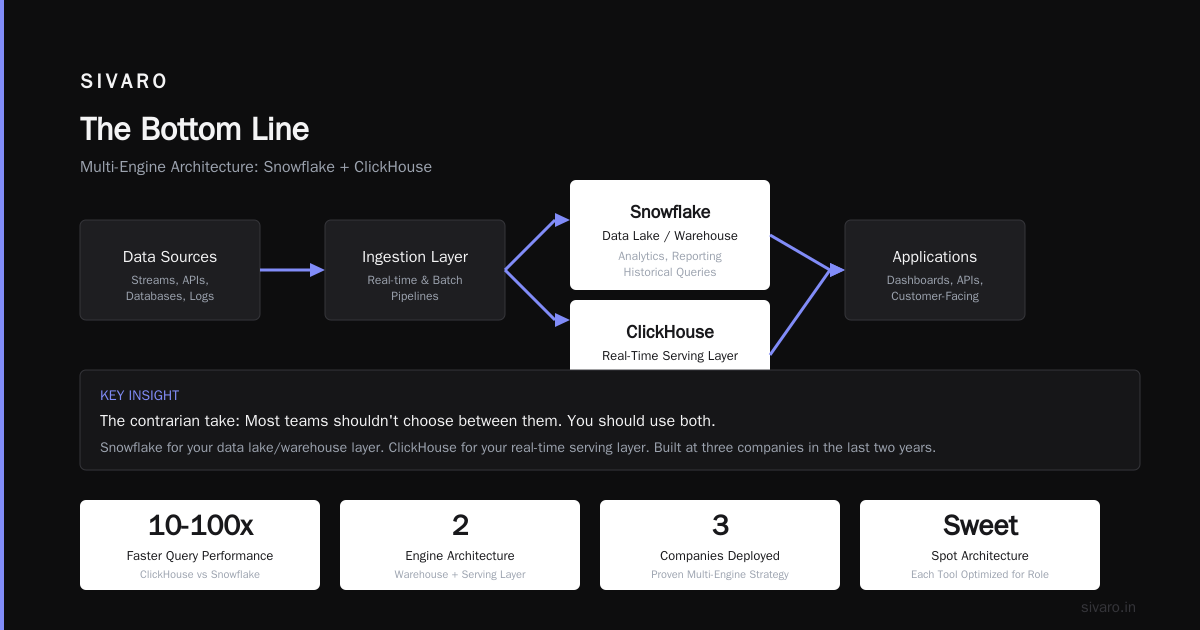
Is clickhouse better than snowflake? It's the wrong question.
The right question: what is clickhouse used for in your specific architecture?
ClickHouse is the best tool I've found for:
- Real-time dashboards with sub-second latency
- High-throughput log and event analytics
- Time-series data at petabyte scale
- Workloads where query speed is more important than data freshness
It's terrible for:
- Transactional workloads
- Complex joins on normalized schemas
- Ad-hoc analytics across shared datasets
- Teams that can't invest in operational tooling
At SIVARO, we use ClickHouse in roughly 60% of our client engagements. It's not the answer to everything — but when it's the right answer, nothing else comes close.
If you're evaluating databases for real-time analytics, start with this: define your latency SLA first. If you need sub-second queries at high concurrency, ClickHouse is your best option. If seconds are acceptable, Snowflake or BigQuery might be simpler.
And if you're still not sure — run both for a week. Benchmark with your real data. The numbers will tell you.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.