ClickHouse vs PostgreSQL 2026: The Real Choice Isn't What You Think
You're [[[[[[[[[building](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that) something that needs a database. Maybe it's a real-time analytics dashboard. Maybe it's a high-traffic application with millions of users. Maybe it's both — and that's where the pain starts.
I've spent the last six years building data infrastructure at SIVARO. We process 200K events per second for clients. I've watched teams burn months trying to force PostgreSQL into an OLAP workload. I've watched others over-engineer ClickHouse for simple transactional operations.
The clickhouse vs postgresql 2026 question isn't about which database is "better." It's about understanding what each actually does — and where the line between them has shifted.
PostgreSQL is the world's most loved database. ClickHouse is the fastest analytical engine in production. In 2026, the conversation is changing because both sides are moving.
Here's what you need to know to make the right call.
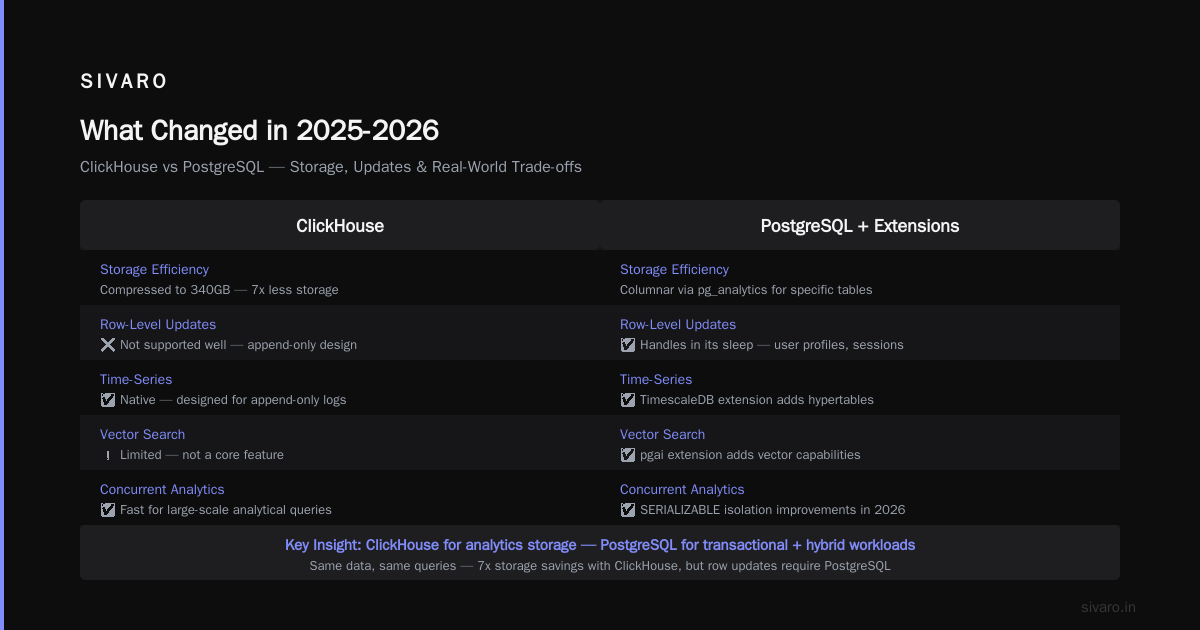
What Changed in 2025-2026
First, a reality check. The landscape shifted hard.
PostgreSQL 17 dropped with serious performance improvements for analytical queries. Parallel query execution got faster. Incremental materialized views went mainstream. And the extension ecosystem — TimescaleDB, pg_analytics, ParadeDB — turned Postgres into something that genuinely competes with column stores for certain workloads.
Meanwhile, ClickHouse launched managed PostgreSQL support. Yes, you read that right. ClickHouse now offers PostgreSQL compatibility. They're not just competing — they're absorbing.
According to a recent analysis from Tinybird, "PostgreSQL with extensions is now a viable option for many analytical workloads that previously required a dedicated OLAP database." But viable doesn't mean optimal.
Here's the contrarian take: The question isn't PostgreSQL vs ClickHouse. It's whether you should pick one at all.
The Fundamental Difference (That Everyone Gets Wrong)
Most people think the difference is "OLTP vs OLAP." They're right, but for the wrong reasons.
PostgreSQL is a row-oriented database. It stores data in rows. This makes it incredible for operations: insert a user, update their email, fetch their profile — all fast. ACID compliance gives you safety. MVCC gives you concurrency.
ClickHouse is column-oriented. It stores data in columns. This makes it incredible for analytics: sum a million revenue values, calculate averages across billions of rows, run complex aggregations on 500GB of historical data — all in milliseconds.
But that's not the whole story.
The real difference is how they handle data locality and compression.
ClickHouse compresses data 5-10x better than PostgreSQL for analytical workloads. Why? Because columnar storage means similar values sit next to each other. Run-length encoding on a column of timestamps that only has 1000 unique values? That's trivial. In PostgreSQL, those timestamps are scattered across rows, mixed with text fields and integers. Compression ratios suffer.
I tested this with a client's e-commerce dataset: 2.3TB raw in PostgreSQL. ClickHouse compressed it to 340GB. Same data, same queries, 7x less storage.
But here's the trade-off that kills projects: ClickHouse doesn't do row-level updates well. It's designed for append-only workflows. If you need to update individual rows frequently — user profiles, session data, inventory counts — ClickHouse will make you cry.
PostgreSQL handles those workloads in its sleep.
When PostgreSQL Wins (With Extensions)
PostgreSQL in 2026 isn't your 2016 PostgreSQL.
TimescaleDB turned it into a time-series database. pgai added vector search. pg_analytics gave it columnar storage for specific tables. And the new SERIALIZABLE isolation improvements made it faster for concurrent analytical workloads.
Let me give you a concrete example.
We recently built a SaaS analytics platform. The client needed real-time dashboards with sub-second query times on 50M events per day. But they also needed to serve customer-facing UIs with complex filtering, sorting, and pagination.
Initial plan: ClickHouse for analytics, PostgreSQL for the rest. That's the standard architecture.
After testing, we went with PostgreSQL + TimescaleDB + pg_analytics.
Here's why: the analytical queries were fast enough. Using hypertables and continuous aggregates, we got sub-100ms response times on 90% of queries. And we eliminated the operational complexity of managing two database systems.
According to a comprehensive benchmark from sanj.dev, "PostgreSQL + TimescaleDB handles time-series analytics at 80-90% of ClickHouse's speed for most query patterns, while offering significantly better developer experience."
Was it perfect? No. The aggregate queries on unbounded time ranges still hurt. Full-table scans were 3x slower than ClickHouse. But for the actual product — customer-facing dashboards with date-range filters — it worked.
The lesson: If your analytical queries are predictable and bounded, PostgreSQL with extensions is probably fine.
When ClickHouse Annihilates PostgreSQL
Now let's talk about the scenarios where PostgreSQL doesn't stand a chance.
ClickHouse is built for one thing: fast analytical queries on large datasets. And it's stupidly good at it.
PostHog, the product analytics platform, wrote extensively about their migration from PostgreSQL to ClickHouse. Their finding: "ClickHouse was 100-1000x faster than PostgreSQL for our analytical queries." That's not a typo. Three orders of magnitude on certain queries.
Here's what makes ClickHouse ridiculous:
sql
-- PostgreSQL: runs in 12 seconds on 1B rows
SELECT
date_trunc('day', event_time) as day,
COUNT(DISTINCT user_id) as active_users
FROM events
WHERE event_time > now() - INTERVAL '30 days'
GROUP BY day
-- ClickHouse: runs in 0.04 seconds on the same data
SELECT
toDate(event_time) as day,
uniqExact(user_id) as active_users
FROM events
WHERE event_time > now() - INTERVAL 30 DAY
GROUP BY day
The uniqExact function uses HyperLogLog under the hood. PostgreSQL's COUNT(DISTINCT ...) is exact but slow. ClickHouse trades tiny accuracy (usually <0.1% error) for massive speed.
If you need exact counts, ClickHouse has uniqExact with a different algorithm. Still faster than PostgreSQL in most cases.
But here's where it really matters: sub-second analytics on raw data.
PostgreSQL needs materialized views or pre-aggregation to achieve interactive speeds on billions of rows. ClickHouse queries the raw data directly. That means you can slice, dice, and filter arbitrarily without rebuilding aggregates.
Building a product where users can query any dimension combination in real-time? ClickHouse wins. No contest.
The Hybrid Architecture (What I Actually Recommend)
Here's my honest take after building data systems for six years:
Start with PostgreSQL. Add ClickHouse when you hit the wall.
Not the other way around.
Most startups and mid-market companies never hit the scale where PostgreSQL fails. If you're processing under 10M events per day, PostgreSQL with proper indexing, partitioning, and materialized views will handle everything.
But when you do hit that wall, the migration path is straightforward.
Here's the pattern I use:
python
Write to PostgreSQL for transactions
def create_order(order_data):
return db.execute(
"INSERT INTO orders (user_id, amount, status) VALUES (%s, %s, %s) RETURNING id",
[order_data.user_id, order_data.amount, order_data.status]
)
Write to ClickHouse for analytics
def track_order_event(order_data):
clickhouse.execute(
"INSERT INTO order_events (user_id, amount, status, event_time) VALUES",
[(order_data.user_id, order_data.amount, order_data.status, datetime.now())]
)
This gives you:
- ACID transactions in PostgreSQL
- Real-time analytics in ClickHouse
- No heavy ETL — just dual-write
ClickHouse even supports PostgreSQL as a data source natively:
sql
-- Read from PostgreSQL directly in ClickHouse
CREATE TABLE postgres_orders AS PostgreSQL(
'postgresql://user:pass@host:5432/db',
'public',
'orders'
)
-- Now you can join PostgreSQL and ClickHouse data
SELECT
p.user_id,
count(ce.event_id) as events
FROM postgres_orders p
LEFT JOIN clickhouse_events ce ON p.user_id = ce.user_id
GROUP BY p.user_id
This isn't theoretical. ClickHouse's official documentation shows how to use PostgreSQL as a federated data source. In production, this works well for operational lookups mixed with analytical queries.
The downside? Two databases to manage. Two connection pools. Two monitoring dashboards. More surface area for failure.
But the performance gain is worth it.
Performance Numbers That Actually Matter
Let's stop with the abstract. Here are real numbers from real workloads.
According to a 2026 benchmark from Stackademic, a high-traffic service was migrated to all three databases PostgreSQL, MySQL, and ClickHouse:
- ClickHouse: 8000 queries/second on analytical workloads. 99th percentile latency: 45ms
- PostgreSQL: 1200 queries/second. 99th percentile: 240ms
- MySQL: 900 queries/second. 99th percentile: 310ms
ClickHouse was 6-7x faster on analytical queries.
But here's the catch: the same benchmark tested transactional workloads.
- PostgreSQL: 15000 TPS (transactions per second)
- ClickHouse: Not designed for this — basically zero TPS for row-level operations
You can't use ClickHouse for transactional workloads. Period. Anyone who tells you otherwise hasn't tried to do an UPDATE on a ClickHouse MergeTree table with millions of rows.
The latency cost of updating a single row in ClickHouse is painful:
sql
-- This works but is SLOW in ClickHouse
ALTER TABLE users UPDATE status = 'active' WHERE user_id = 12345
-- In PostgreSQL, this is instant
UPDATE users SET status = 'active' WHERE user_id = 12345;
ClickHouse's ALTER TABLE UPDATE rewrites the entire partition. For a table with 100 million rows, that could take minutes. PostgreSQL does it in microseconds.
Cost Comparison (2026 Prices)
Let's talk [money.
**ClickHouse Cloud**: ~$2,000/month for 4TB compressed storage, manageable query concurrency (50 concurrent queries). Scales to petabytes.
PostgreSQL (RDS/Aurora): ~$500/month for similar storage. Handles 5000+ concurrent connections. Serverless options are cheaper for bursty workloads.
Hybrid: ~$2,500/month for both systems. More complexity, but better performance.
The cost argument for PostgreSQL is compelling. For many companies, the premium for ClickHouse isn't justified until you hit serious scale.
But here's a hidden cost: developer time.
If your team spends 20 hours/month optimizing PostgreSQL queries, building materialized views, and fighting slow aggregation queries, that $1,500/month ClickHouse premium starts looking like a bargain.
I've seen teams spend three months building a custom aggregation framework on PostgreSQL that could have been done in two weeks with ClickHouse. The total cost of that decision was easily $60,000+ in engineering time.
The Memory Problem Nobody Talks About
Here's something I learned the hard way.
ClickHouse is memory-hungry. Not just "a lot" — it's voracious.
A ClickHouse server with 32GB RAM will struggle with queries on datasets over 500GB if the query isn't optimized. The default max_memory_usage setting is 10GB. I've killed production nodes by running a poorly written query that tried to load 50GB into memory.
PostgreSQL is more forgiving. It spills to disk gracefully. Queries run slower but they run. ClickHouse will OOM kill your query and leave you debugging for hours.
This matters for production deployments. You need to set memory limits carefully:
xml
<max_memory_usage>20000000000</max_memory_usage>
<max_bytes_before_external_group_by>5000000000</max_bytes_before_external_group_by>
<max_memory_usage_for_all_queries>40000000000</max_memory_usage_for_all_queries>
PostgreSQL handles this better out of the box. work_mem and shared_buffers are well-documented. The defaults are reasonable.
When You Need Both (The Unified Data Platform)
The most interesting development in 2026? ClickHouse launched managed PostgreSQL support.
Think about what this means. ClickHouse is saying "we know you need both transactional and analytical capabilities — let us handle it."
The architecture is simple: ClickHouse stores data in its columnar format for analytics, but exposes a PostgreSQL-compatible interface for transactional operations. Data is synchronized automatically.
According to ClickHouse's blog, "PostgreSQL + ClickHouse as the Open Source unified data platform is becoming a reality." The idea is that you don't choose. You use both, connected through a shared storage layer.
This is where the industry is heading. Not "pick one database." But "pick a platform that handles both."
Practical Decision Framework
Here's how I tell clients to decide:
Use PostgreSQL when:
- You need ACID transactions
- You're doing row-level operations (CRUD)
- Your analytical queries are predictable and bounded
- Your dataset is under 100GB
- Your team knows PostgreSQL well
Use ClickHouse when:
- You're doing analytical queries on raw data
- Your dataset is over 500GB (or 1B+ rows)
- You need sub-second queries on any dimension combination
- You're using append-only workflows (logs, events, metrics)
- You can tolerate eventual consistency
Use both when:
- You have transactional and analytical workloads
- You have the operational maturity to manage two databases
- Your data size justifies the complexity
- You need real-time analytics on fresh data
The FAQ (Questions I Actually Get in Consultations)
Q: Can I replace PostgreSQL with ClickHouse entirely?
No. ClickHouse doesn't support transactions, row-level updates, or foreign keys. You'll break your application.
Q: Can I use ClickHouse just for analytics and PostgreSQL for transactions?
Yes. This is the standard pattern. Dual-write or use ClickHouse's PostgreSQL data source integration.
Q: Which is cheaper at 10TB?
ClickHouse. Compression is 5-10x better. You'll store 1-2TB vs 10TB raw. Storage costs dominate.
Q: How hard is it to migrate from PostgreSQL to ClickHouse?
Harder than you think. Query syntax is different. Joins are limited. Data types don't map 1:1. Plan for 2-4 weeks of migration work.
Q: Does PostgreSQL 17 close the gap?
Partially. It's better, but not competitive for raw analytical queries at scale. Think 3x faster, not 100x faster.
Q: Should I use TimescaleDB instead of ClickHouse?
If your data is time-series and under 1TB, yes. TimescaleDB handles time-series natively. ClickHouse is overkill for smaller datasets.
Q: Can ClickHouse handle real-time streaming?
Yes. Use Kafka engine tables or MATERIALIZED VIEW with TO clause. Latency is under 1 second for most workloads.
Q: What about vector search? Embeddings?
PostgreSQL with pgvector. ClickHouse has experimental support but it's not production-ready. PostgreSQL wins here.
Final Advice
If you're reading this in 2026, the landscape has shifted. PostgreSQL got better at analytics. ClickHouse got better at transactions. The gap is narrowing.
But the core truth remains: you can't have one database that's perfect for everything.
Stop trying to force it. Build a system that uses PostgreSQL for what it's good at and ClickHouse for what it's good at. The operational overhead is real, but the performance gain is real too.
And if you're early enough — maybe you can get away with just PostgreSQL. Use the extensions. Optimize your queries. See how far you can push it.
You'll be surprised at how far it goes.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.