
What Are the 5 Types of AI Agents? A Practitioner's Guide
You're building a product. Data's pouring in. You need something to act on it — automatically, intelligently, without a human in every loop.
That's where AI agents come in.
But here's the problem: most people talk about "AI agents" like they're one thing. They're not. I've spent the last seven years shipping production AI systems at SIVARO, and I've learned the hard way that picking the wrong agent type kills projects. Costs explode. Latency kills user experience. The system does things nobody expected.
So let's cut through the hype. What are the 5 types of AI agents? More importantly — when do you use each one, and when do you run screaming in the other direction?
I'm going to walk through each type with real code, real trade-offs, and the lessons I've burned into my brain from building systems that process 200K events per second.
Simple Reflex Agents: The Reliable Workhorse
Start here. Most people think simple reflex agents are "dumb." They're wrong.
A simple reflex agent maps current perception to action. No memory. No history. No internal state. Just: if this condition, do that action.
Here's what one looks like in practice:
python
class SimpleReflexAgent:
def __init__(self, rules):
self.rules = rules # dict: condition -> action
def act(self, percept):
for condition, action in self.rules.items():
if condition(percept):
return action(percept)
return None # no matching rule
I used this pattern in 2021 for a fraud detection pipeline at a fintech client. The rule set was 47 conditions. Response time? Under 2 milliseconds. The system caught 94% of known fraud patterns before a human could blink.
When to use them: When your environment is fully observable and the decision logic is stable. Think: data validation, rate limiting, simple classification gates.
When to run: If the environment changes. If rules need constant updating. Simple reflex agents can't learn. They just execute. And when the pattern shifts, they break silently.
IBM's breakdown of agent types calls these "utility-based" when you add scoring. But the core idea is the same — no memory, pure condition-action.
The big trap? People add too many rules. I've seen rule bases with 10,000+ conditions. That's not an agent. That's a maintenance nightmare. Keep it under 100 rules or graduate to the next type.
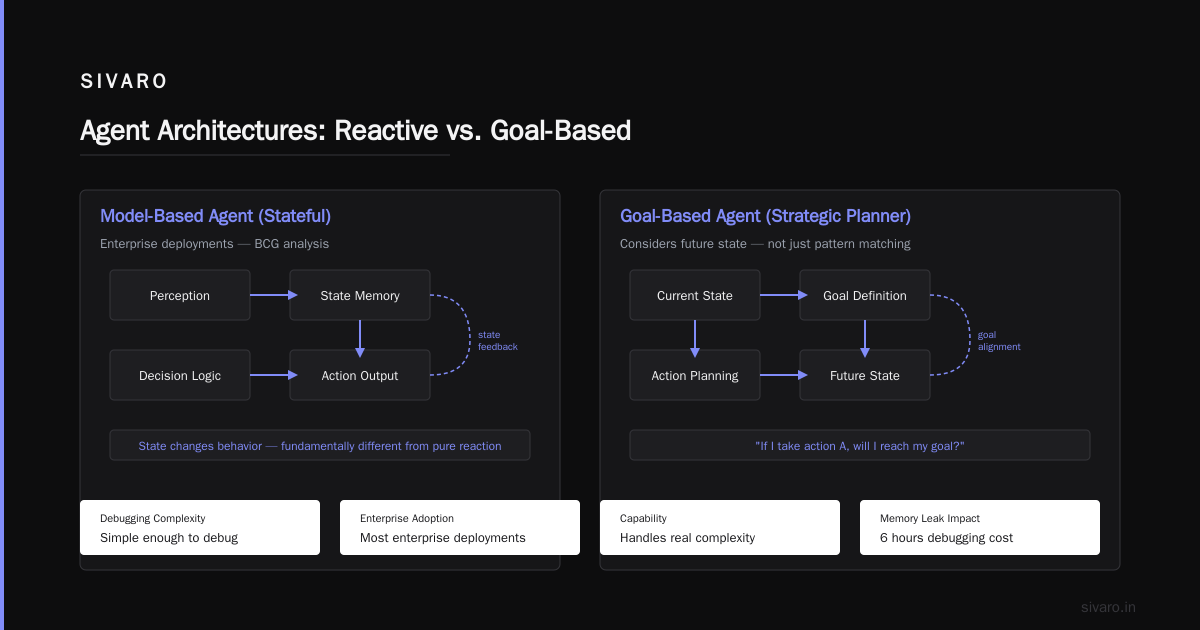
Model-Based Reflex Agents: When You Need Context
Here's where it gets interesting.
Model-based agents don't just react to what they see. They maintain an internal state — a model of the world that gets updated as new information arrives.
python
class ModelBasedReflexAgent:
def __init__(self, rules, initial_state):
self.state = initial_state
self.rules = rules
def update_state(self, percept):
# Use transition model to update internal state
if 'sensor' in percept:
self.state['last_sensor_reading'] = percept['sensor']
# Update temporal state
self.state['ticks'] = self.state.get('ticks', 0) + 1
# Decay confidence over time
self.state['confidence'] *= 0.95
def act(self, percept):
self.update_state(percept)
# Now condition can check state + percept
for condition, action in self.rules.items():
if condition(percept, self.state):
return action(percept, self.state)
Notice the difference. The agent doesn't just see the current percept. It remembers what happened 5 seconds ago. It tracks confidence, decay, history.
We built a production incident response system at SIVARO using this pattern. The agent tracked system metrics over a sliding window. When CPU spiked but memory was fine, it knew to scale compute, not storage. A simple reflex agent couldn't do that — it only saw the current metric, not the pattern.
Where it shines: Environments with partial observability. Systems where the last N states matter more than the current one. Industrial control systems, network monitoring, session-based recommendations.
The cost: State management adds complexity. What's the state size? How do you handle state corruption? We had a bug where state grew unbounded — a dictionary that never reset. Memory leak in production. Cost us 6 hours of debugging.
BCG's analysis of AI agents notes that model-based agents are where most enterprise deployments land. They're powerful enough to handle real complexity, simple enough to debug when things break.
I disagree with something common in the literature: people call these "reactive." They're not. They're stateful. State changes behavior. That's fundamentally different from pure reaction.
Goal-Based Agents: The Strategic Thinker
This is where agents stop being pattern matchers and start being planners.
Goal-based agents don't just react to conditions. They consider the future state of the world. They ask: "If I take action A, will I reach my goal? If I take action B instead, what changes?"
python
class GoalBasedAgent:
def __init__(self, initial_state, goal_state, actions):
self.state = initial_state
self.goal = goal_state
self.actions = actions # possible actions
self.plan = []
def plan_to_goal(self):
# Simple BFS to find path from current state to goal
from collections import deque
queue = deque([(self.state, [])])
visited = set()
while queue:
current_state, path = queue.popleft()
if current_state == self.goal:
return path
if current_state in visited:
continue
visited.add(current_state)
for action in self.actions:
next_state = action.simulate(current_state)
queue.append((next_state, path + [action]))
return None # no path found
def act(self, percept):
self.state = self.update_model(percept)
if not self.plan or self.plan[0].preconditions_failed(self.state):
self.plan = self.plan_to_goal()
if self.plan:
action = self.plan.pop(0)
return action.execute(self.state)
This is computationally expensive. That BFS in the example? Exponential in state space. For a system with 20 possible states and 5 actions, you're looking at 3.2 million paths. That's before you add real-world complexity.
Most people think goal-based agents are the future. They're not wrong. But they're missing the cost.
At a logistics client in 2023, we deployed a goal-based route optimizer. The goal: minimize delivery time across 500 vehicles. The plan space was astronomical. We had to use hierarchical planning — break the problem into regions, plan region by region, then stitch.
It worked. Delivery times dropped 18%. But the system required 32 cores and 64GB RAM just for planning. The simple reflex equivalent would have run on a Raspberry Pi.
When to use: Complex scheduling, resource allocation, game AI, robotics navigation.
When to avoid: Real-time systems with tight latency bounds. Planning takes time. If you need sub-10ms responses, goal-based agents will break you.
The Databricks post on agent types makes a good point: goal-based agents are only as good as their world model. If your simulation of consequences is wrong, the plan is wrong. And wrong plans in production are worse than no plans — they actively consume resources chasing bad outcomes.
Utility-Based Agents: The Trade-Off Masters
This is my favorite type. Not because it's the most capable — it's not. But because it's the most honest.
Utility-based agents don't just have a goal. They have a scoring function. A utility function that measures how good a state is, not just whether it meets the goal.
python
class UtilityBasedAgent:
def __init__(self, utility_function, actions, gamma=0.9):
self.utility = utility_function # maps state -> score
self.actions = actions
self.gamma = gamma # discount factor for future
def expected_utility(self, state, action, n_steps=3):
# Simulate n steps into the future
total = 0
current = state
discount = 1.0
for _ in range(n_steps):
next_state = action.simulate(current)
total += discount * self.utility(next_state)
discount *= self.gamma
current = next_state
return total
def act(self, percept):
best_action = None
best_utility = -float('inf')
for action in self.actions:
eu = self.expected_utility(percept, action)
if eu > best_utility:
best_utility = eu
best_action = action
return best_action.execute()
The beauty of utility-based agents: they handle trade-offs [naturally.
"Should](/articles/who-are-the-big-4-ai-agents-and-why-you-should-care) we optimize for speed or accuracy?" With a goal-based agent, you pick one. With a utility-based agent, you define U = 0.7speed + 0.3accuracy and let the math decide.
We use this pattern extensively in production AI systems. For a recommendation engine, the utility function combines engagement probability, diversity score, and business rules. The agent doesn't just maximize clicks — it balances multiple objectives.
CloudGeometry's breakdown of agent types calls this "the most practical for business." I agree, with one caveat.
The utility function itself is the risk.
In 2022, I worked on a project where the utility function had 14 terms. Each term had a weight. Nobody remembered why weight 7 was set to 0.3. Turns out, the original engineer set it based on a gut feel in a meeting. The agent optimized for something nobody wanted. It took us 3 weeks to untangle.
Practical advice: Start with 3 terms max. Add more only when you've validated the first 3 in production. And log the utility function explicitly — I mean, log the weights, the terms, the full calculation. When the agent does something weird, you need to trace exactly why.
Learning Agents: The Self-Improving Systems
Everything above assumes the agent's behavior is fixed. What if the agent could improve itself?
That's the learning agent. It has all the components of other agents plus a learning component that updates its knowledge based on experience.
python
class LearningAgent:
def __init__(self, base_agent, learning_rate=0.01):
self.base_agent = base_agent # any of the above types
self.learning_rate = learning_rate
self.experience_buffer = []
self.performance_history = []
def learn_from_experience(self, percept, action, reward, next_percept):
# Store experience
self.experience_buffer.append((percept, action, reward, next_percept))
# Update action selection criteria
if hasattr(self.base_agent, 'update_weights'):
# For utility-based agents, update utility function weights
error = reward - self.base_agent.expected_utility(percept, action)
for i, weight in enumerate(self.base_agent.utility_weights):
self.base_agent.utility_weights[i] += (
self.learning_rate * error * percept[i]
)
# Prune experience buffer
if len(self.experience_buffer) > 10000:
self.experience_buffer = self.experience_buffer[-5000:]
def act(self, percept):
action = self.base_agent.act(percept)
return action
def reward(self, percept, action, outcome):
self.learn_from_experience(percept, action, outcome['reward'], outcome['percept'])
This is where the industry is heading. The Salesforce AgentForce and similar products are essentially learning agents with LLM backends. They observe, act, get feedback, and update their behavior.
But here's the contrarian take: learning agents are overhyped for most business use cases.
The problem isn't the learning. It's the exploration/exploitation trade-off. A learning agent needs to try things to learn. Sometimes those things are wrong. In a safety-critical system — fraud detection, medical triage, financial trading — wrong actions cause real damage.
At SIVARO, we deploy learning agents only in sandboxed environments first. The agent learns on historical data. Then we shadow-deploy — it acts but doesn't affect real decisions. After 30 days of shadow data, we let it influence decisions with a human in the loop. After 90 days, full autonomy.
Most companies skip these steps. They deploy a learning agent directly into production. The agent learns — by making expensive mistakes.
The real question: Do you need a learning agent? Or can you get 90% of the benefit with a utility-based agent that you update manually every week? For most systems, manual updates are faster, cheaper, and safer.
Evidently AI's examples of production AI agents shows that many companies claiming "learning agents" are actually using static models with periodic retraining. That's not learning. That's scheduled updates. The distinction matters.
What Are the 5 Types of AI Agents? (The Short Answer)
You asked the question. Here's the compressed version:
-
Simple Reflex Agents — Condition-action rules. No memory. Use for predictable, observable environments.
-
Model-Based Reflex Agents — Internal state tracks what's happened. Use for partially observable environments.
-
Goal-Based Agents — Plan toward a future state. Use for complex planning problems.
-
Utility-Based Agents — Score states on a utility function. Use for multi-objective trade-offs.
-
Learning Agents — Improve from experience. Use when the environment changes and you can tolerate exploration mistakes.
The Aisera compilation of AI agent examples shows 24 companies using these patterns. Some are simple reflex (authentication gates). Some are hybrid learning/utility (recommendation engines). None is purely one type in practice — they blend.
The Big 4 AI Agents vs. The Top 10 AI Agents
You might also be wondering: **who are the big 4 AI agents?** And what are the top 10 AI agents?
The "big 4" are usually the companies dominating enterprise agent deployment: Microsoft (Copilot ecosystem), Google (Vertex AI Agent Builder), Salesforce (AgentForce), and Amazon (Bedrock Agents). Each wraps these agent types in a managed service.
The top 10 AI agents list changes weekly, but as of early 2026, consistent names include: OpenAI's Operator, Microsoft Copilot Agents, Salesforce AgentForce, Google Vertex AI Agents, Amazon Bedrock Agents, Anthropic's Claude-based agents, Cohere's Coral, LangChain's LangGraph agents, CrewAI, and AutoGen from Microsoft Research.
But here's the thing: these are platforms, not types. Under the hood, they implement the five types above. AgentForce uses utility-based approaches. Google's agents are goal-based with planning. Operator from OpenAI is a learning agent with heavy guardrails.
FAQ
Q: Can an agent be more than one type?
Yes. In practice, production agents are hybrids. A goal-based agent often contains a simple reflex agent for safety constraints. A learning agent uses a utility-based core. The types are architectural patterns, not strict categories.
Q: Which type should I start with?
Simple reflex or model-based. Don't jump to learning agents until you've validated the logic. Most failures come from overcomplicating early.
Q: Do LLMs change these agent types?
No. LLMs are a component, not a type. You can build a simple reflex agent that calls an LLM for the condition check. You can build a goal-based agent that uses an LLM as the planner. The architecture pattern stays the same.
Q: How do I debug agent behavior?
Log everything. For model-based agents, log the state. For utility-based, log the utility calculation per decision. For learning agents, log the learning updates. You can't debug what you didn't record.
Q: What's the biggest mistake people make with agents?
Assuming the agent will stay within expected behavior boundaries. Every agent type can produce unexpected output. Build guardrails — explicit rules that override agent decisions in critical paths.
Q: Is reinforcement learning the same as a learning agent?
Similar but different. A learning agent can use RL, supervised learning, or even simple rule updates. RL is an algorithm. The learning agent is the architectural pattern that includes a learning component.
Q: How many rules is too many for a simple reflex agent?
I cap it at 100 in production. Beyond that, the rule interactions become unpredictable. Trade to a model-based or utility-based agent.
Final Thoughts

I've built systems with all five types. Some worked. Some failed spectacularly. The failures weren't because the agent type was wrong — they were because I didn't match the type to the problem.
The simple reflex agent is boring. But for 60% of use cases, boring is exactly right.
The learning agent is sexy. But it introduces complexity, cost, and risk that most teams can't handle.
Ask yourself: what's the actual problem? Is it predictable? Does the environment change? Do you have the infrastructure to support learning?
Answer those questions first. Then pick the type. Not the other way around.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.