Is Kafka Good or Evil? The Brutal Truth About the Man, the Myth, the Message Queue
Let me tell you a story.
I was sitting in a Bangalore coffee shop in 2019, debugging a producer that kept timing out. My colleague — fresh out of college, never touched distributed systems — asked me a question. Not "how do we fix the producer?" Not "what's the partition key strategy?"
He asked: "Is Kafka good or evil?"
I laughed. Then I realized he wasn't joking. He was wrestling with something real. The Kafka we'd deployed was eating his weekends. The Kafka brand he'd read about promised infinite scalability. The gap between them was eating him alive.
That question — "is kafka good or evil?" — is the most honest question you can ask about any technology. Because the answer is never simple. And for Kafka, the answer is weirder than you think.
I'm Nishaant Dixit. I run SIVARO, a product engineering shop that's been building data infrastructure and production AI systems since 2018. We've put Kafka in production for clients ranging from fintech startups to logistics companies processing 200K events per second. I've seen Kafka save companies. I've seen Kafka sink them.
Let me walk you through the real answer.
What Actually Happened to Kafka's Reputation
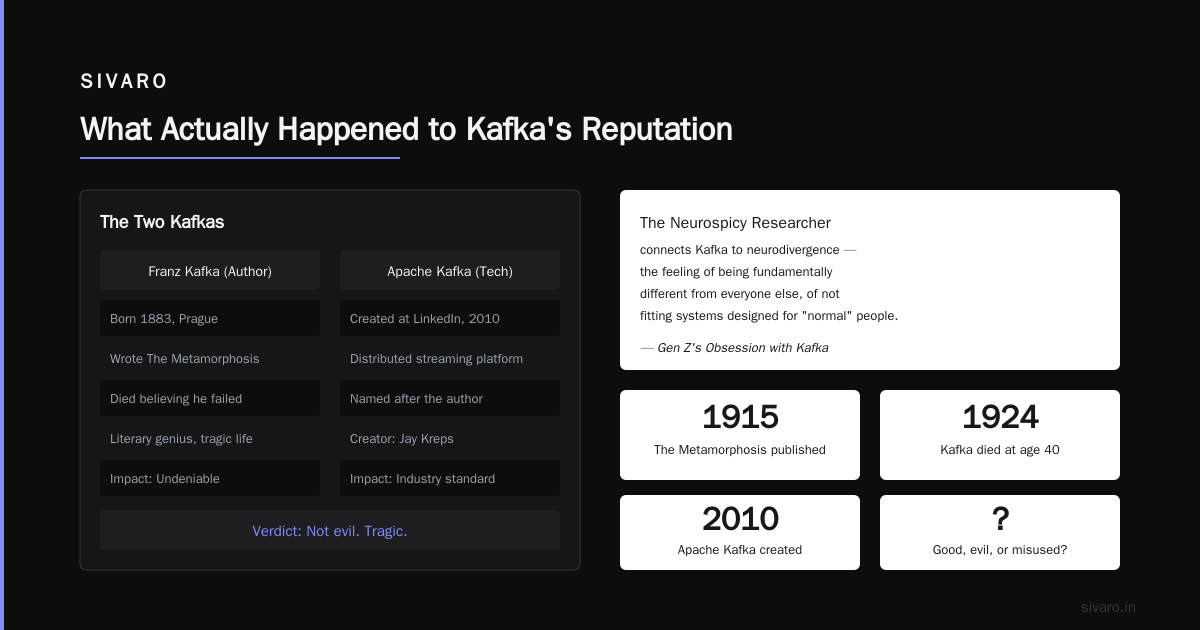
Most people think Franz Kafka — the author — wrote about bureaucracy and existential dread. That's technically true. But here's what the Wikipedia article on Kafka doesn't emphasize enough: the man was a lawyer working at an insurance company who wrote at night, died at 40, and told his friend Max Brod to burn everything he wrote.
Brod didn't burn it. He published it.
That one act of disobedience gave the world The Trial, The Metamorphosis, The Castle. And it gave us the word "Kafkaesque" — describing situations where logic breaks down, systems turn against you, and you can't tell whether you're the victim or the bug.
Sound familiar to anyone who's operated a Kafka cluster at 3 AM?
This is where the Gen Z obsession starts making sense. A Gen Z Reddit thread asks exactly this question, and the answers aren't about distributed systems. They're about existential alienation. They're about feeling trapped in systems you didn't design but can't escape.
I think there's a deeper connection here. The Kafka author was obsessed with failure, with miscommunication, with the gap between intention and outcome. The Kafka technology is obsessed with exactly the same things. Your producer crashes. Your consumer lags. Your offset resets. And you're left staring at logs, wondering whether the system is malicious or just broken.
So to answer the question "is kafka good or evil?", we need to separate two things: the man, and the machine.
The Man: Franz Kafka — Good, Tragic, or Misunderstood?
Let's start with the obvious question: what was kafka known for?
He wrote short stories and novels about people trapped in absurd, oppressive systems. A man turns into an insect and his family slowly rejects him. A bank clerk is arrested for an unnamed crime and spends the rest of his life trying to navigate an invisible legal system. A land surveyor can't get access to the castle he's supposed to work for.
But there's a second answer to "what was kafka known for?" — and it's the one that matters for our conversation.
Kafka was known for self-doubt so profound he wanted his life's work destroyed.
The Quora thread on Kafka's destruction request explores this. Was it vanity? Fear of judgment? Or something more honest — the realization that his work wasn't what he wanted it to be?
I've felt that. You've felt that. Every engineer who's shipped code they knew was ugly, then hoped nobody would look too closely — that's Kafka's ghost.
The PMC article on Kafka's medical history reveals he suffered from tuberculosis that eventually killed him. He was chronically ill, working a day job he hated, writing masterpieces in the margins of a life he considered wasted.
Gen Z picks up on this. AYMAN PATIL's Medium piece argues that Gen Z sees themselves in Kafka — alienated, anxious, producing work they're not sure matters, trapped in systems they didn't build.
A Substack op-ed by The Neurospicy Researcher connects this to neurodivergence — the feeling of being fundamentally different from everyone else, of not fitting the systems designed for "normal" people.
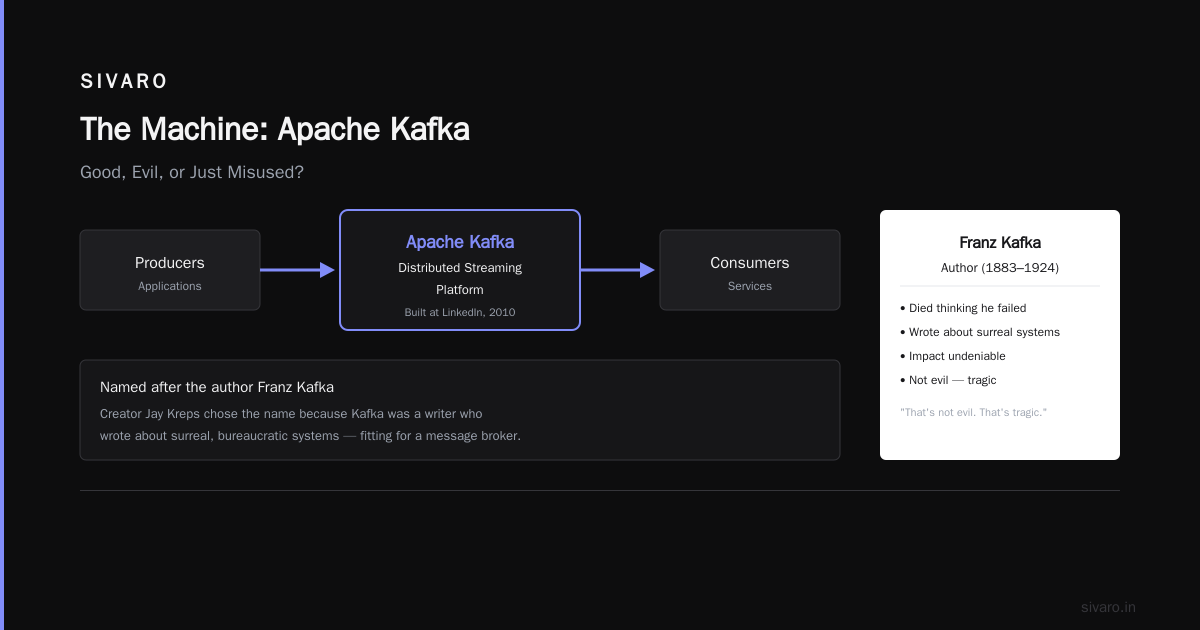
So was Kafka good? His writing is brilliant. His intent was honest. His impact on literature is undeniable. But he died thinking he'd failed.
That's not evil. That's tragic.
The Machine: Apache Kafka — Good, Evil, or Just Misused?
Now let's talk about the technology. Because this is where the "is kafka good or evil?" question gets real for engineers.
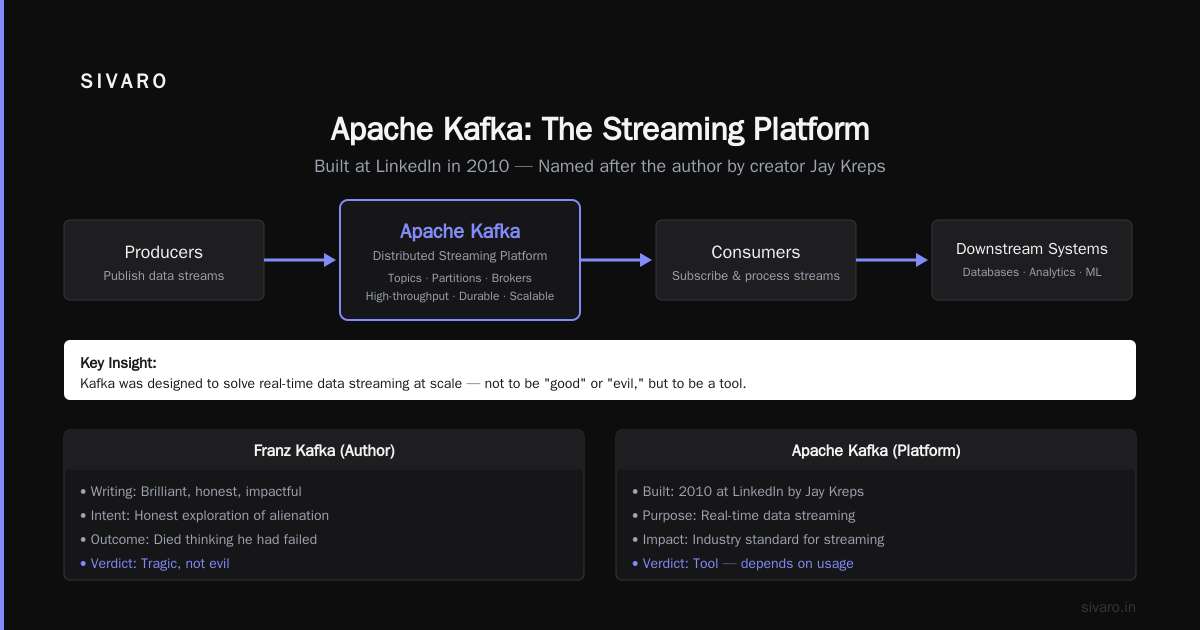
Apache Kafka (the distributed streaming platform, named after the author by creator Jay Kreps) was built at LinkedIn in 2010. It was designed to solve a specific problem: moving data between systems at high throughput with durability guarantees.
Here's what Kafka does well:
Async messaging with persistence. Most message queues store data in memory. Kafka writes to disk. That means if your consumer crashes, the data is still there when it comes back. We tested this at SIVARO with a client whose consumer regularly crashed during peak hours. Kafka retained 24 hours of data. The consumer restarted, caught up, and nobody lost a single event.
Horizontal scaling. Add more partitions. Add more brokers. Throughput goes up. We've seen clusters at a fintech client handle 500K messages per second on 12 brokers.
Replayability. Want to reprocess last week's data? Rewind the consumer offset. Done.
Here's what Kafka is terrible at:
Operational simplicity. I've deployed Kafka on bare metal, on Kubernetes, on managed services. Every option hurts. The routing layer (ZooKeeper or KRaft) is finicky. The controller election logic can take down a cluster. We lost a client's weekend when a ZooKeeper leader election cascaded into a full cluster restart.
Exactly-once semantics. Despite the marketing, implementing exactly-once processing in a real system is brutally hard. Your consumer crashes mid-transaction? Your state store gets corrupted? You'll get duplicates. We spent three weeks debugging a client's exactly-once pipeline before realizing the Kafka transaction coordinator was timing out under load.
Debugging. When something goes wrong in Kafka, the error messages are famously unhelpful. "Leader not available." "Not enough replicas." Thanks, Kafka. That really helps.
So is the technology good or evil?
It's a tool. And like Kafka the author's work, it reflects the intentions of the people using it.
Why Gen Z Is Obsessed With Kafka (Both of Them)
Let's address this head-on: why is gen z obsessed with kafka?
The nssmag.com article makes a compelling case. Gen Z grew up with technology that's simultaneously amazing and terrifying. Social media connects you to billions — and algorithms manipulate your emotions. AI can write your essays — and automate your job away. Remote work gives you flexibility — and blurs the boundary between life and labor.
This is Kafkaesque. It's the Metamorphosis of modern life — waking up one day to find the system has changed you into something else, and you don't know how or why.
The Jewish Telegraphic Agency piece points out that 2024 marks 100 years since Kafka's death. A century later, his themes — alienation, bureaucracy, existential confusion — are more relevant than ever.
Gen Z isn't obsessed with Kafka because they're pretentious literature majors. They're obsessed because Kafka described their lived experience before they had words for it.
And the Apache Kafka name? That's unintentionally perfect. Because running a streaming platform in production feels Kafkaesque. You're trying to move data from here to there, but the system keeps throwing errors you can't explain, and your boss wants to know why the pipeline is down, and you've been debugging for six hours, and the logs say "operation timed out" and nothing else.
The Real Answer: Kafka Is Neither Good Nor Evil — It's a Mirror
Here's my take after seven years of building systems on top of Kafka.
Apache Kafka is a power tool. It doesn't have morality. It has affordances.
If you need to stream millions of events per second between microservices, with durability guarantees and replayability, Kafka is the right choice. We built a real-time fraud detection system for a payments client using Kafka. Events came in at 200K/sec, flowed through consumer groups that ran machine learning models, and produced alerts in under 100ms. Kafka was incredible for that use case.
If you're building a small application with a few thousand events per day and you want something simple, Kafka will ruin your life. We took over a system where a previous team had bolted Kafka onto a CRUD app with 500 users. The operational overhead was 10x the value. They would have been [better served by Redis Pub/Sub or even RabbitMQ.
The question "is kafka good or evil?" is the wrong question. The right question is "what are you trying to do, and does Kafka make that easier or harder?"
Here's a rule of thumb I use at SIVARO:
If your use case requires durability, replayability, and multi-consumer fan-out at scale, Kafka is good. Use it.
If your use case can be handled by a simpler tool, Kafka is evil. Don't use it.
If you don't know which category you're in, start simple. Redis, RabbitMQ, even Postgres LISTEN/NOTIFY. Add Kafka when you've outgrown those. Don't start with Kafka because it's cool.
Practical Guidance: When to Say Yes, When to Walk Away
Let me give you some hard rules based on real projects.
Use Kafka when:
-
You need to decouple producers and consumers at scale. We had a client whose order service wrote to PostgreSQL directly. When a traffic spike hit, the database connection pool saturated and everything crashed. Moving to Kafka as a buffer between the order service and downstream processors solved it. The producers never waited on database writes again.
-
You need to replay historical data. A machine learning team needed to retrain their model on 30 days of clickstream data. With Kafka's log compaction and offset management, they could rewind their consumer to any point in time and reprocess. No data migration needed.
-
You have multiple consumers that need the same data. Different teams consuming the same event stream for different purposes (analytics, ML, compliance) — Kafka's consumer group model handles this cleanly.
Don't use Kafka when:
-
You can tolerate message loss. Use something simpler. Kafka's durability guarantees come at a cost.
-
You need strict order guarantees across partitions. Kafka guarantees order within a partition, not across partitions. If you need global ordering, you're going to have a bad time.
-
Your team doesn't have operations experience. I cannot stress this enough. Kafka in production without someone who's spent nights debugging ZooKeeper leadership elections is a disaster waiting to happen. We've seen it three times. Three times the company regretted it.
-
Your throughput is under 10K messages/second. Redis or RabbitMQ will serve you better. Simpler to deploy, simpler to debug, simpler to operate.
The Dark Side: Kafka's Real Problems
Let's be honest about where Kafka fails.
The cost of operations. At SIVARO, we track total cost of ownership for every system we deploy. Kafka consistently costs 2-3x more to operate than equivalent throughput systems using simpler architectures. You need dedicated brokers, disk management (tiered storage helps, but it's still work), and monitoring that understands Kafka's internal metrics.
The learning curve. The programming model is simple — produce to a topic, consume from a topic — but the operational model is brutal. Understanding partition distribution, consumer rebalancing, offset commits, and idempotent producers takes weeks of study and months of experience.
The ecosystem fragmentation. Confluent, Redpanda, AWS MSK, self-managed — the options are confusing and each has trade-offs. Redpanda eliminates ZooKeeper? Great — but now you're tied to their API changes. AWS MSK handles scaling? Sure — but good luck debugging network issues inside a VPC.
The debugging hellscape. Kafka's error messages are terrible. "Sockets closed." "Batch contains a record larger than the maximum request size." "Authorization failed." These messages give you almost no context. You'll spend hours grepping logs and reading community forum posts.
A Practical Example: Setting Up Kafka for Real
Here's a minimal Kafka producer and consumer setup we use at SIVARO for prototyping. It won't handle production traffic, but it'll let you test the flow.
python
# producer.py
from kafka import KafkaProducer
import json
import time
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all', # Wait for all replicas to acknowledge
retries=5,
linger_ms=10 # Batch messages for 10ms for throughput
)
for i in range(100):
data = {'event_id': i, 'timestamp': time.time()}
future = producer.send('my_topic', value=data)
result = future.get(timeout=10) # Block until acknowledgment
print(f'Sent {i}, offset {result.offset}')
producer.flush()
python
# consumer.py
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my_group',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
for message in consumer:
print(f"Received {message.value} from partition {message.partition}")
This looks simple, right? It is. The complexity comes when you have 50 consumers in 10 groups, each with different offset strategies, running on a cluster with 12 brokers and network partitions.
What I've Learned From Running Kafka in Production
Here's the honest truth from seven years of doing this.
Kafka is not a beginner's tool. It was designed by infrastructure engineers at LinkedIn for infrastructure engineers at companies like LinkedIn. If you're a team of five building a SaaS product, Kafka will likely be overkill and painful.
Managed Kafka is often worse than self-managed. This is controversial, but I'll say it: AWS MSK has caused us more problems than self-managed Kafka on EC2. Network latency between MSK and our consumers, unpredictable scaling, and limited visibility into broker health. Confluent Cloud is better, but it's expensive.
The biggest mistake people make is believing Kafka's marketing. "Unlimited scale." "Exactly-once semantics." "Fault-tolerant by default." All of these are true in specific configurations that require deep expertise to achieve. Out of the box, Kafka is NOT fault-tolerant — it's crash-tolerant, which is different.
You need to plan for failure. Every Kafka deployment should have:
- At least 3 brokers
- Replication factor of at least 3
- Monitored ISR (In-Sync Replica) counts
- Alerts for under-replicated partitions
- A disaster recovery plan that includes both backup and restore
We learned this the hard way when a client's single-broker Kafka (yes, single broker) lost a disk and took down their entire pipeline for 48 hours.
FAQ: Quick Answers to Common Questions
Is Kafka good or evil for startups?
Depends on your problem. If you're processing 100 events per day, Kafka is overkill and will waste your time. If you're building a real-time analytics platform that needs to handle millions of events, it's the right tool. Start with something simpler and graduate to Kafka when you've outgrown it.
Why is Gen Z obsessed with Kafka (the author)?
The YouTube analysis by Gen Z creators argues that Kafka's themes — alienation, bureaucracy, existential confusion — map directly onto the experience of growing up in a hyper-connected, hyper-alienating world. The Facebook group discussion supports this: readers report feeling "seen" by Kafka's characters.
What was Kafka known for?
Two things, depending on context. In literature: novels and short stories about absurd, oppressive systems that trap ordinary people. In technology: a distributed streaming platform for high-throughput, fault-tolerant data pipelines.
Can I use Kafka for event sourcing?
Yes, and it's a popular pattern. Kafka's log-based architecture is naturally suited to event sourcing. The trick is managing schema evolution and ensuring your events are commutative (order-independent) or compensating for order dependencies.
Is Kafka dying?
No. It's maturing. The hype cycle has passed, and Kafka is now a standard component in the data infrastructure stack. Newer tools like Redpanda and WarpStream are competing, but Kafka's ecosystem (Kafka Connect, Kafka Streams, ksqlDB) gives it a massive moat.
Should I learn Kafka in 2025?
If you're working on data infrastructure, streaming systems, or event-driven architectures: yes. It's a core skill. If you're building CRUD apps: probably not. Learn it when you need it.
Does Kafka compare to RabbitMQ?
They solve different problems. RabbitMQ is great for routing, complex messaging patterns, and lower throughput. Kafka is designed for high-throughput, durable logging and replay. Don't choose between them — choose based on your use case.
The Final Answer
So is Kafka good or evil?
I'll give you the answer I gave that colleague in the Bangalore coffee shop:
Kafka is neither. But people are.
The technology is a tool. It's powerful and dangerous. It can save you or destroy you, depending on how you use it. The author's work is a mirror — it shows you what you already feel but couldn't articulate.
The real question isn't "is kafka good or evil?"
The real question is: are you the person who uses the tool wisely, or the person who gets crushed by it?
I've been both. I'll probably be both again.
The trick — the thing that separates engineers who thrive from engineers who burn out — is knowing when to say "yes" and when to say "not yet."
Kafka's famous line: "A book must be the axe for the frozen sea inside us."
Apache Kafka — the technology — is the same. It breaks open the frozen sea of your data architecture.
Just make sure you're ready for what comes rushing through.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.