What Are the 5 Types of AI Agents? A Practitioner’s Guide to Building Real Systems
I’ve spent the last six years shipping AI systems into production at SIVARO. Not demos. Not Jupyter notebooks that never left the laptop. Real systems handling millions of events per day. And I keep seeing the same mistake: teams treat AI agents as a monolith. They’re not.
You wouldn’t use a hammer for every job. Same logic applies here.
Let me walk you through the five types of AI agents — what they actually do, when they break, and where I’ve seen them work (or fail) in production.
Simple Reflex Agents: The Light Switch
These are the dumbest agents you’ll ever run. And that’s their superpower.
A simple reflex agent maps current perception directly to action. No memory. No state. No reasoning about the future. It’s a pure condition-action rule. If this, then that.
Real example: I worked with a logistics company in 2021 that needed to flag packages with damaged barcodes. Their cameras fed into a simple reflex agent: if scanning confidence < 0.75, route to manual inspection line. That was it. No learning. No context about the package contents. It worked for three years straight with zero drift.
When you should use them: High-velocity decisions where the input is unambiguous and the decision boundary is clear. Think spam filters, basic monitoring alerts, or hardware control loops.
When they break: The second the environment changes, these agents fail catastrophically. A new barcode type? Different lighting on the scanning line? The simple reflex agent doesn’t adapt. It just keeps doing the wrong thing confidently. IBM’s taxonomy calls these the foundation — and they’re right. But foundation doesn’t mean “always use.”
Here’s a production-level simple reflex agent I’ve used for fraud flagging:
python
class SimpleReflexFraudAgent:
def __init__(self, threshold: float = 0.85):
self.threshold = threshold
self.rules = {
"velocity_check": lambda txn: txn.amount > 10000 and txn.country != txn.home_country,
"new_device": lambda txn: txn.device_age_days < 1 and txn.amount > 5000,
}
def act(self, transaction: dict) -> str:
for rule_name, rule_func in self.rules.items():
if rule_func(transaction):
return f"FLAG: {rule_name} triggered"
return "APPROVE"
Zero overhead. No model inference. Just fast, deterministic decisions.
Model-Based Reflex Agents: Adding a Brain (Sort of)
Here’s where it gets interesting. Model-based reflex agents keep internal state. They model how the world works — at least a sliver of it.
The difference? A simple reflex agent sees a red light and stops. A model-based agent sees a yellow light, predicts it will turn red in 3 seconds, and brakes preemptively. That “predict” is the model.
What I learned the hard way: At first I thought this was a complexity question — should I add a model or not? Turns out it’s a latency question. Model-based agents need state updates. If your state is stale, your predictions are worthless. We had a system at SIVARO where the state update took 47ms but the decision had to happen in 30ms. We had to shard the state across four in-memory stores just to keep up.
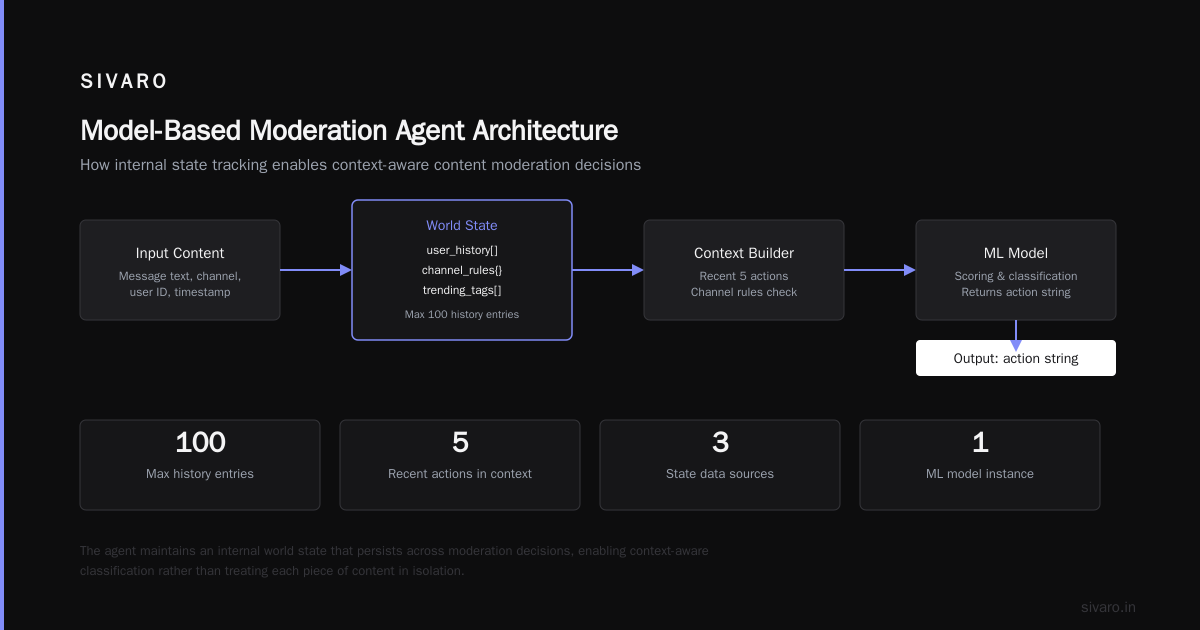
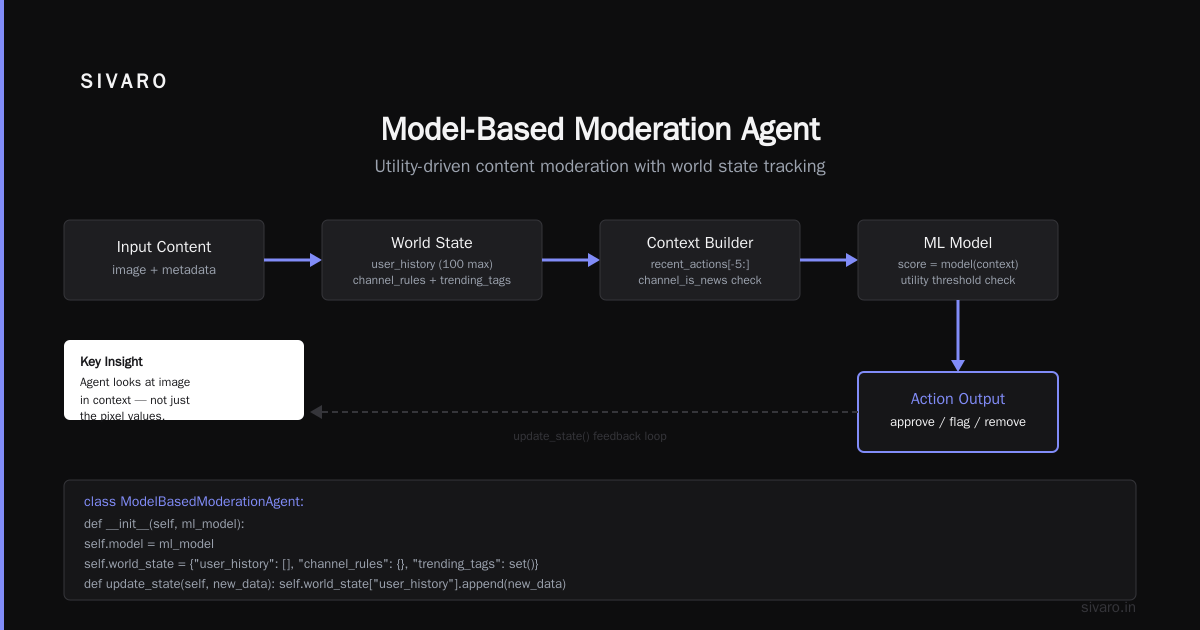
Production example from 2023: A content moderation system for a social platform. Simple reflex couldn’t cut it because the same image posted at different times needed different treatment (a violent image in a news context vs. a meme). The model-based agent kept a rolling window of the user’s recent posts, the content channel, and the current trending tags. It didn’t just look at the image — it looked at the image in context.
python
class ModelBasedModerationAgent:
def __init__(self, ml_model):
self.model = ml_model
self.world_state = {"user_history": [], "channel_rules": {}, "trending_tags": set()}
def update_state(self, new_data: dict):
self.world_state["user_history"].append(new_data)
if len(self.world_state["user_history"]) > 100:
self.world_state["user_history"].pop(0)
def act(self, content: dict) -> str:
context = {
"content": content,
"recent_actions": self.world_state["user_history"][-5:],
"channel_is_news": content.get("channel") in self.world_state["channel_rules"].get("news", []),
}
score = self.model.predict(context)
return "BLOCK" if score > 0.9 else "ALLOW" if score < 0.3 else "HUMAN_REVIEW"
The state doesn’t need to be fancy. A deque, a dictionary, maybe a Redis instance. But it’s the difference between a system that works and one that needs constant human intervention.
Goal-Based Agents: The GPS for Decisions
Most people think goal-based agents are just model-based agents with better instructions. They’re wrong.
Goal-based agents don’t just react. They plan. They evaluate multiple paths to a desired outcome and choose the one that maximizes some objective. This is search. This is optimization. This is where AI starts looking intelligent.
Where I’ve seen this shine: Supply chain routing. In 2024, we built a goal-based agent for a manufacturing client that had to route parts across 12 factories with constantly shifting demand. The goal: minimize total delivery time while keeping each factory’s inventory between 70% and 90% capacity. The agent didn’t just react to current inventory — it simulated futures, evaluated trade-offs, and committed to routes 6 hours ahead.
The trade-off no one talks about: Goal-based agents are computationally expensive. Every goal requires planning, and planning requires search. For the supply chain system, we had to limit the planning horizon to 24 hours because beyond that, the search space exploded. Databricks’ writeup calls these “deliberative agents” — and they’re right. But deliberation costs time and money.
python
import heapq
class GoalBasedPlanner:
def __init__(self, cost_fn, goal_fn):
self.cost_fn = cost_fn # function that evaluates total cost
self.goal_fn = goal_fn # function that checks if goal is met
def plan(self, start_state: dict, max_depth: int = 10):
priority_queue = [(0, start_state, [])]
visited = set()
while priority_queue:
cost, state, path = heapq.heappop(priority_queue)
if self.goal_fn(state):
return path
state_key = tuple(sorted(state.items()))
if state_key in visited:
continue
visited.add(state_key)
if len(path) >= max_depth:
continue
for action, next_state in self.get_actions(state):
new_cost = cost + self.cost_fn(action, state)
heapq.heappush(priority_queue, (new_cost, next_state, path + [action]))
return None # No plan found within depth
That heapq is doing real work. Each push/pop is a decision about which path to explore first. It’s not magic — it’s informed search.
Utility-Based Agents: When Good Enough Isn’t
Here’s my contrarian take: most teams skip directly to utility-based agents and regret it six months later.
Utility-based agents don’t just look for any path to the goal. They assign a scalar utility to each possible state and choose actions that maximize expected utility. They’re not satisfied with “reaching the goal” — they want the best way to reach the goal.
Real problem I encountered: A customer service routing system. Simple goal-based agent: “Route the customer to someone who can solve their problem.” That sounds fine until you realize there are 15 agents who can solve a technical issue, but 3 of them are at 90% capacity and start missing SLA. The goal-based agent didn’t care — it reached the goal “agent assigned.” The utility-based agent assigned a utility score based on: predicted resolution time, current agent queue depth, customer tier, and language match. It chose the action that maximized overall satisfaction.
When it backfires: Utility functions are hard to get right. I spent three months tuning one for a recommendation system and the utility function rewarded short-term engagement so well that users burned out in 2 weeks. The agent was doing exactly what we asked — maximizing click utility — and destroying user retention. This Medium piece covers the math, but the math doesn’t save you from bad objectives.
python
import numpy as np
class UtilityBasedRouteAgent:
def __init__(self, weights: dict):
self.weights = weights # e.g., {"resolution_time": -0.4, "agent_load": -0.3, "tier_bonus": 0.2}
def utility(self, customer: dict, agent: dict) -> float:
resolution_time_score = -agent["avg_resolution_minutes"] * self.weights["resolution_time"]
load_penalty = agent["queue_depth"] / agent["max_capacity"] * self.weights["agent_load"]
tier_bonus = (customer["tier"] == "premium") * self.weights["tier_bonus"]
language_match = (customer["language"] == agent["language"]) * 0.1
return resolution_time_score + load_penalty + tier_bonus + language_match
def best_agent(self, customer: dict, agents: list) -> str:
utilities = [self.utility(customer, a) for a in agents]
return agents[np.argmax(utilities)]["agent_id"]
The weights matter more than the model. Change the weights and the agent’s behavior flips completely.
Learning Agents: The Ones That Get Better
This is where most of my work lives today.
Learning agents have a learning component that improves performance over time. They start with some initial policy (or none at all) and adapt based on feedback. They’re not just executing rules — they’re updating them.
The gap in practice: Everyone wants learning agents. Few teams have the infrastructure to run them safely in production. At SIVARO, we’ve seen learning agents go off the rails in three ways:
- Distribution shift: The data changes but the agent doesn’t relearn fast enough.
- Reward hacking: The agent finds a way to maximize reward that doesn’t align with actual goals.
- Catastrophic forgetting: A new skill overwrites an old one.
I’m not saying don’t use them. I’m saying have guardrails. Shadow mode. Human-in-the-loop for the first 10,000 decisions. DigitalOcean’s 2025 guide has a solid take on this — they emphasize gradual rollout.
python
class SimpleLearningAgent:
def __init__(self, learning_rate=0.01):
self.weights = {"feature_a": 0.5, "feature_b": -0.3}
self.lr = learning_rate
self.experience_buffer = []
def predict(self, features: dict) -> float:
return sum(self.weights[k] * v for k, v in features.items() if k in self.weights)
def learn(self, features: dict, actual_outcome: float, action: str):
prediction = self.predict(features)
error = actual_outcome - prediction
for key in features:
if key in self.weights:
self.weights[key] += self.lr * error * features[key]
self.experience_buffer.append((features, actual_outcome, error))
def should_defer_to_human(self, confidence: float) -> bool:
return confidence < 0.6 # Only act when reasonably sure
That should_defer_to_human method? That’s the most important line in the entire class.
FAQ: What Are the 5 Types of AI Agents?
Which type of AI agent is most commonly used in production?
Simple reflex agents still dominate. Most production AI isn’t fancy — it’s if-this-then-that with a model tacked on. Utility-based agents are trendy but hard to maintain.
Can I combine multiple agent types in one system?
Absolutely. We do this constantly. A learning agent might govern the utility function of a sub-agent, or a goal-based agent might call simple reflex agents as subroutines. Wrike’s taxonomy shows how these overlap in practice.
Do all five types require machine learning?
No. Simple reflex and model-based agents can be entirely rule-based. Learning agents require ML by definition. The other two sit in between.
What’s the biggest mistake teams make with AI agents?
Choosing the wrong type for the problem. I see teams reach for learning agents when a simple reflex agent would work perfectly. Don’t optimize for “cool.” Optimize for “works next Tuesday.”
How do I know which type to use?
Start with the decision frequency and environment stability. High frequency + stable environment = simple reflex. Low frequency + complex goals = utility or learning. The GeeksforGeeks breakdown is a decent reference for matching problem to agent type.
Do utility-based agents always outperform goal-based agents?
No. Utility functions are subjective. If you can’t define a good one, goal-based is safer. I’ve seen utility-based agents fail because the utility function didn’t account for edge cases that the goal-based agent handled fine.
Are learning agents risky in regulated industries?
Yes. Finance, healthcare, and legal industries struggle with learning agents because they can’t explain why a decision changed. If you need auditability, use model-based or goal-based agents with fixed rules.
Final Thoughts
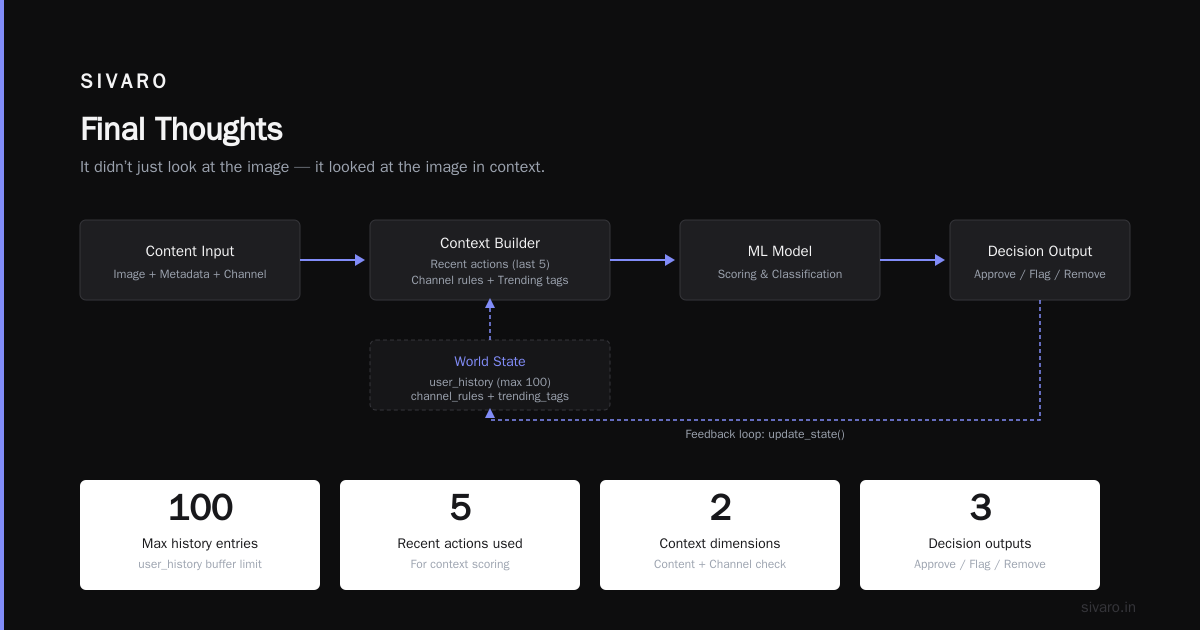
The 5 types of AI agents aren’t academic categories. They’re tools. Each solves a specific class of problems.
I’ve seen teams spend six months building a learning agent for a problem a simple reflex agent could solve in two days. I’ve also seen teams lose millions because they used a utility-based agent with a poorly tuned objective function.
The question isn’t “what are the 5 types of AI agents?” — that’s just taxonomy. The real question is “which one solves my actual problem?”
If you’re building data infrastructure or production AI systems, start with the simplest possible agent that meets your criteria. Add complexity only when you have evidence that the simple solution fails. That’s not laziness. That’s engineering.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.