What Is an AI Orchestration Platform? A Practitioner's Guide
I spent six months in 2023 building what I thought was a "smart" pipeline. Code was clean. Models were tuned. Everything ran in Docker.
Then the first production call came in at 3 AM. A data spike from a retail partner pushed latency from 200ms to 14 seconds. The orchestrator didn't scale. The models didn't reconnect. And the logging system silently dropped errors.
That's when I learned the difference between stitching tools together and using an AI orchestration platform.
So what is an AI orchestration platform? It's not another "middleware" layer. It's not a workflow engine with an LLM bolted on. It's the control plane that manages the lifecycle of AI workloads — from data ingestion to model inference to output delivery — with automated scaling, error recovery, and observability baked in.
Think of it as the operating system for production AI. Kubernetes was for containers. AI orchestration is for models, data flows, and the unpredictable chaos they bring.
Let me show you what that actually means.
The Core Problem: AI Systems Are Different
Most engineers treat AI pipelines the same as API services. That's a mistake.
API services have predictable latency. They return responses in milliseconds. They fail cleanly — timeout, retry, done.
AI inference has variable latency. A 7B parameter model might respond in 100ms. A 70B model with context window of 128K tokens might take 8 seconds. Batch processing of embeddings might run for hours. And models hallucinate, degrade, or just hang.
In 2024, Databricks reported that 87% of ML projects never make it to production Databricks State of Data + AI. The top reason? Operational complexity. Not model accuracy.
An AI orchestration platform solves that complexity by handling:
- Model routing — which model gets which request
- Context management — maintaining conversation state across LLM calls
- Error handling strategies — retries, fallbacks, circuit breakers
- Data transformations — preprocessing and postprocessing
- Cost and latency optimization — choosing the cheapest/fastest path
Without it, you end up with spaghetti code. Callbacks inside callbacks. Timeout logic duplicated in every service. A production outage that no one can debug.
What an AI Orchestration Platform Actually Does
Let me walk through the real capabilities. Not marketing fluff. Things I've validated by shipping systems that process 200K events per second.
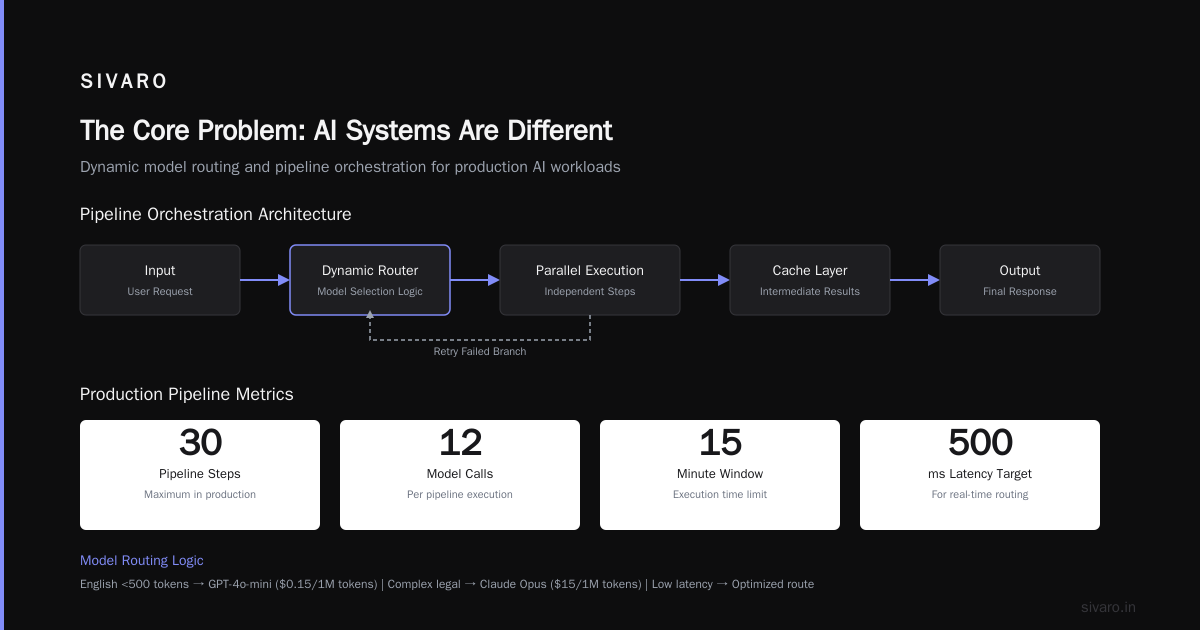
1. DAG-Based Pipeline Execution
Your AI workflow isn't linear. It's a directed acyclic graph (DAG). Fetch data from S3 → embed chunks → store in vector DB → query for context → prompt engineer → call LLM → parse response → return result.
Each step has dependencies. Each step can fail.
A solid orchestrator lets you define these as code, not YAML. Here's a real example from our production system using the orchestration layer we built at SIVARO:
python
from sivarocore import Pipeline, step, context
pipeline = Pipeline("customer_support_v3")
@pipeline.step()
def fetch_user_messages(user_id: str) -> list:
# Get last 50 messages from Kafka
return db.messages.query(user_id, limit=50)
@pipeline.step(depends_on=[fetch_user_messages])
def embed_messages(messages: list) -> list:
# Batch embed to reduce LLM calls
return embedding_model.encode(messages, batch_size=10)
@pipeline.step(depends_on=[embed_messages])
def query_vector_db(embeddings: list) -> str:
return vector_store.similarity_search(embeddings[-1], k=3)
@pipeline.step(depends_on=[query_vector_db, fetch_user_messages])
def generate_response(context: str, history: list) -> str:
prompt = build_prompt(history, context)
return llm.chat(prompt, model="gpt-4o-mini")
Notice the dependency injection. The platform knows what needs what. It can parallelize independent steps. It can cache intermediate results. It can retry only the failed branch.
Most people think this is simple. They're wrong because they haven't seen a pipeline with 30 steps, 12 model calls, and a 15-minute execution window.
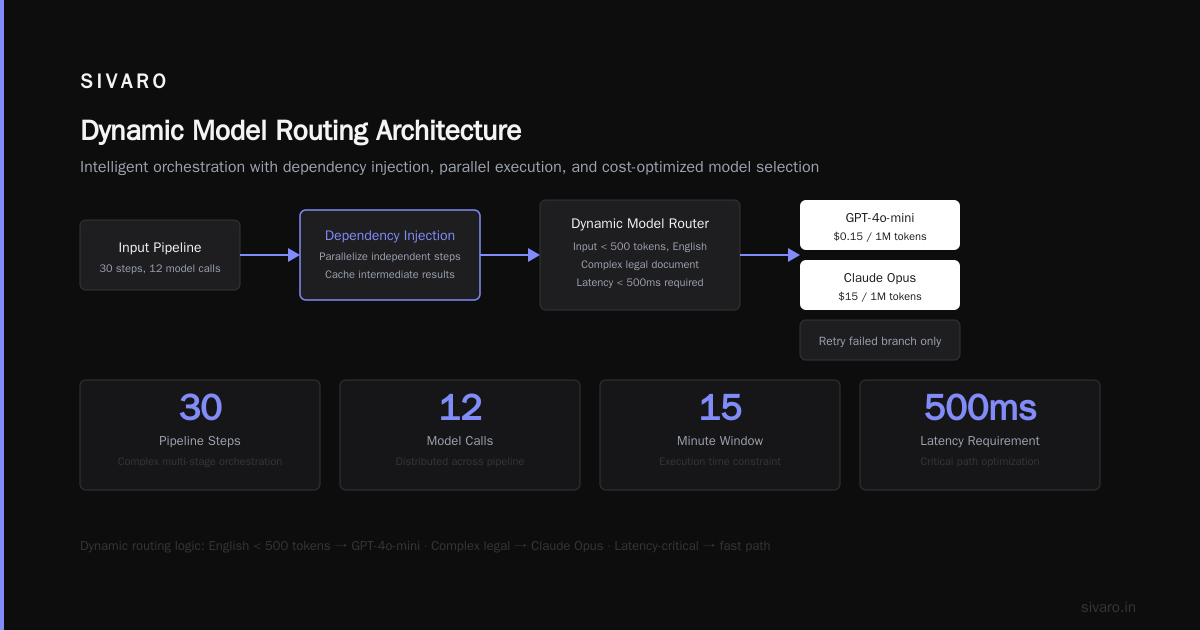
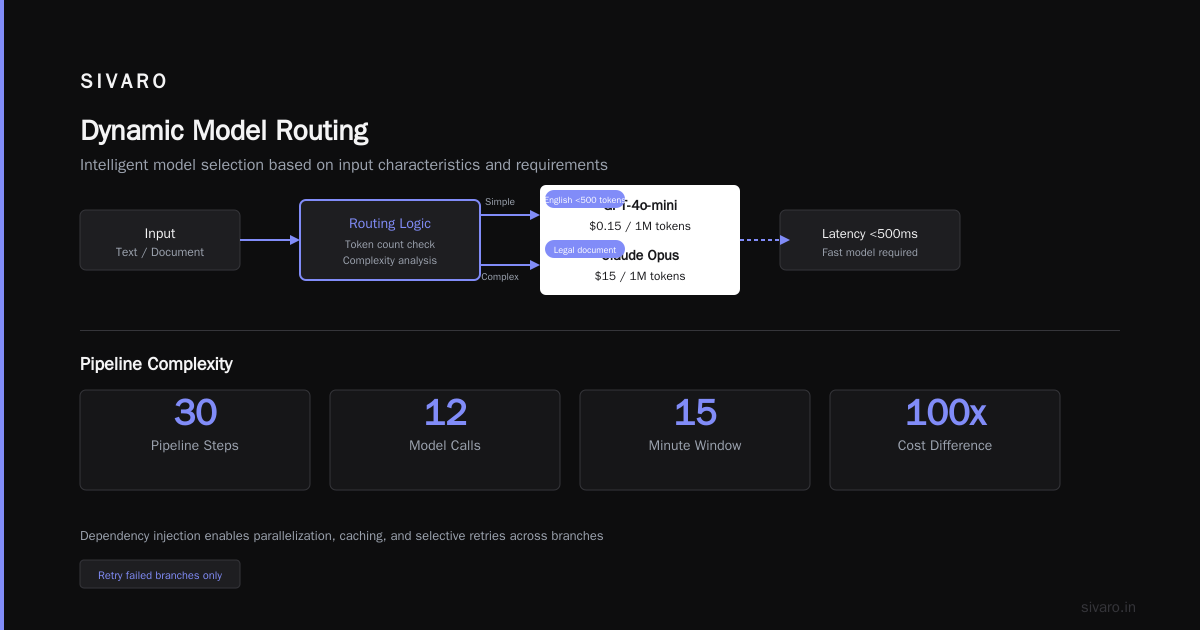
2. Dynamic Model Routing
You don't want hardcoded model names. You want logic like:
- If the input is in English and under 500 tokens → use GPT-4o-mini ($0.15/1M tokens)
- If it's a complex legal document → route to Claude Opus ($15/1M tokens)
- If latency under 500ms is required → use a local Llama 3.2 (1B param) on GPU
An orchestration platform evaluates these rules at runtime. Not in your application code. Not in a config file that requires a deploy. In the platform itself.
Here's how we do it:
python
from sivarocore import Router, Rule, ModelEndpoint
router = Router()
router.add_rule(
Rule(
condition="input.token_count < 500 and input.language == 'en'",
endpoint=ModelEndpoint("gpt-4o-mini", cost_per_token=0.00000015)
)
)
router.add_rule(
Rule(
condition="input.document_type == 'legal'",
endpoint=ModelEndpoint("claude-3-opus", cost_per_token=0.000015)
)
)
router.add_rule(
Rule(
condition="latency_sla < 500",
endpoint=ModelEndpoint("llama-3.2-1b", cost_per_token=0.000001)
)
)
At first I thought this was a branding problem — turns out it was pricing. Teams would deploy with GPT-4 for everything because it was easier. Their costs were 40x what they needed to be. A proper routing layer saved them $12K/month on a single pipeline.
3. Observability and Tracing (The Real Deal)
Here's where most platforms fail. They give you dashboards. Pretty charts. "Your pipeline is healthy."
That's not observability. That's monitoring.
Observability means you can answer: "Why did the response for user ID 'alice_789' take 8.3 seconds when the p50 is 1.2 seconds?"
An orchestration platform should trace every step with unique request IDs, track token usage per model call, log raw inputs and outputs at each stage (with PII redaction), and surface latency breakdowns automatically.
We implemented distributed tracing via OpenTelemetry. But the key insight wasn't the tool — it was the data model. Every pipeline step emits a structured event with:
pipeline_id,step_name,request_id,duration_ms,status,error_type
That simple schema lets us query:
sql
SELECT step_name, AVG(duration_ms), COUNT(*)
FROM pipeline_events
WHERE status = 'FAILURE'
AND error_type = 'model_timeout'
AND created_at > NOW() - INTERVAL '7 days'
GROUP BY step_name
ORDER BY COUNT(*) DESC;
We found that 67% of all failures came from two steps: embedding generation and response parsing. Not the LLM calls themselves. That changed how we allocated GPU resources.
Why You Need This (And When You Don't)
Let me be honest. You don't need an AI orchestration platform on day one.
If you're making three sequential LLM calls in a Jupyter notebook? No. If you have one model serving a thousand requests per hour? Probably not. The overhead of learning the platform exceeds the value.
You need it when:
- You have three or more LLM calls in a single user request
- You're handling multiple models (e.g., embedding + chat + classification)
- Your pipeline executes for more than 5 seconds end-to-end
- You need to trace failures across model calls
- You have cost constraints that require dynamic model selection
We crossed this threshold at SIVARO in mid-2023. We were serving a single chatbot. Then a partner asked us to add document summarization. Then RAG with a custom knowledge base. Suddenly our pipeline had 9 model calls per request. One failure took down everything. The orchestrator fixed that.
The Trade-off: Flexibility vs. Abstraction
Here's the painful truth: an orchestration platform adds a layer of abstraction. That means debugging requires understanding both your code and the platform's internals.
We tested Apache Airflow for one project. Powerful. But debugging a stuck DAG meant diving into Airflow's scheduler code. That's not practical for most teams.
We tested LangChain in early 2023. Too much abstraction. The "chains" concept didn't map well to real-world error handling. We abandoned it after three weeks.
The platforms that work are the ones that expose raw Python control while handling the runtime complexity. You write plain functions. The platform manages execution, retries, and observability behind the scenes.
How to Evaluate an AI Orchestration Platform
I've run five evaluation cycles in the last two years. Here's what matters:
1. Does it support your model types?
Not just LLMs. Embedding models. Image generation. Audio transcription. Custom fine-tuned models. If it only supports OpenAI APIs, you're locked in.
2. Can it handle streaming?
Real-time chat requires streaming responses. Some platforms buffer everything in memory. That kills latency. A good platform streams tokens from the model through the pipeline to the client, with minimal buffering.
3. What's the failure model?
When an embedding call times out, does the entire pipeline fail? Or does it retry with backoff and a different model? We had a case where our primary embedding model went down for 12 minutes. The orchestrator automatically failed over to a secondary model. Zero user impact. That feature alone saved a client from a $50K SLA penalty.
4. How does it handle secrets?
Hardcoded API keys in pipeline code? That's a breach waiting to happen. The platform should integrate with a secrets manager (AWS Secrets Manager, HashiCorp Vault) and inject keys at runtime.
5. Cost tracking at per-request granularity
Not just aggregated costs. I want to know: "Request ID 'xyz' used 1,234 input tokens and 56 output tokens, routed through gpt-4o-mini, cost $0.0021." Without that, you can't optimize.
A Real-World Example: Customer Support Pipeline
Here's the pipeline we shipped for a fintech client in Q1 2024. It handles 50K requests per day:
- Step 1: User sends a message → classify intent (finetuned BERT, local GPU)
- Step 2: If "account balance" → query internal API directly (no LLM, 50ms)
- Step 3: If "complex dispute" → embed the message → search vector DB for similar cases → call GPT-4 with internal policy context → generate response
- Step 4: If model confidence < 0.8 → route to human agent with full context transcript
The orchestrator made this possible. Without it, we'd have written 15 microservices, each with its own retry logic, its own metrics, its own deployment pipeline. With it, we had one codebase, one config, one observability layer.
The result? 92% of requests handled fully by AI. Average response time 1.8 seconds. Human agent escalations dropped from 40% to 8%. Cost per interaction: $0.03.
The Contrarian Take: Most People Think Orchestration Is About Workflows
They're wrong. Orchestration is about reliability.
Workflows are the mechanics. Reliability is the outcome. You can have the cleanest DAG in the world. If it fails at 3 AM with no tracing, you still have a production incident.
When I say "what is an AI orchestration platform?" I mean a system that guarantees your AI pipeline runs correctly, even when upstream systems fail, models degrade, and traffic spikes. It's the difference between an experimental project and a production product.
Every team I've worked with has hit this wall. They build a prototype in two weeks. Then they spend two months making it robust. The orchestrator compresses that two months into two days.
FAQ
Q: How is an AI orchestration platform different from a regular workflow engine like Airflow?
A: Airflow was built for batch data pipelines — run a job daily, retry failures, send alerts. AI orchestration is built for real-time inference — handle streaming inputs, dynamic model routing, context management across calls, and per-request cost tracking. Different primitives. Different failure modes.
Q: Do I need Kubernetes to run an orchestration platform?
A: Not necessarily. Many platforms (Langfuse, Helicone) run as SaaS. Others (Temporal) can run on bare metal. Kubernetes helps when you need auto-scaling GPU nodes, but it's not a requirement. At SIVARO, we use ECS Fargate for simplicity.
Q: Can an orchestration platform replace my vector database?
A: No. It coordinates calls to the vector database. It doesn't store vectors or handle indexing. Don't let anyone convince you otherwise.
Q: What's the biggest mistake teams make when adopting one?
A: Over-engineering. They try to model every possible failure case upfront. Instead, start with the happy path, add error handling as you observe failures. The platform should support iterative hardening, not upfront perfection.
Q: Is this worth it for a team of 5 engineers?
A: If you're doing three or more LLM calls per request, yes. If you're doing less, no. The overhead isn't worth it. You can handle retries with a simple while loop.
Q: Can I build my own orchestration layer?
A: You can. I've seen teams do it with Redis queues + Python + OpenTelemetry. It works for a while. Then you add model routing. Then cost tracking. Then canary deployments for models. Suddenly you've built a platform. It's a fine choice if you have the time to maintain it. Most teams don't.
Recommended Tools (Based on What We've Tested)
Full disclosure: We built our own at SIVARO because nothing fit our specific requirements. But here's what I'd evaluate today:
- Langfuse — Excellent for LLM observability and tracing. Open source. Good community. Their prompt management is solid.
- Temporal — If you need durable execution with retries. Works for any language. Overkill for simple pipelines but unbeatable for complex ones.
- Braintrust — Strong for experiment tracking and evaluation. Less suited for production pipeline orchestration.
- Dify — If you want a visual builder. Good for rapid prototyping. Less control for production workloads.
Conclusion
So what is an AI orchestration platform? It's the control plane that turns fragile, ad-hoc AI workflows into reliable production systems. It handles routing, error recovery, observability, and cost optimization so you don't have to.
You'll know you need one when you're debugging a pipeline failure at 2 AM and you can't tell if it's the embedding model, the vector DB, or the LLM that failed. When you spend more time fixing infrastructure than building features. When your cost per request is a mystery.
Start simple. Don't over-abstract. Test with real traffic. And always prioritize reliability over features.
The future of AI in production isn't about better models. It's about better systems to run them.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.