Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub
You've got an EKS cluster running Cluster Autoscaler. It [[[[[[[[[[[[works](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/vector-database-comparison-2026-what-actually-works-in)](/articles/what-is-the-10-20-70-rule-for-ai-the-only-framework-that)](/articles/what-is-the-10-20-70-rule-for-ai-the-only-framework-that)](/articles/temporal-workflow-engine-comparison-what-actually-works-in)](/articles/temporal-workflow-engine-comparison-what-actually-works-in)](/articles/temporal-workflow-engine-comparison-what-actually-works-in). Mostly. But those node groups feel like straitjackets — you're paying for instances you don't need, waiting minutes for nodes to spin up, and your SRE team keeps patching ASG configurations by hand.
I've been there. In 2023, I watched a team burn three weeks tuning Cluster Autoscaler for a Spark workload. They never got it right. Switched to Karpenter in three days. [Their bill dropped 32%.
Here's the thing: this Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub isn't just a search query — it's a [[[[[[[[[[playbook](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes)](/articles/karpenter-slack-the-karpenter-channel-and-kubernetes). This article is that playbook. We'll cover the real mechanics, the gotchas that'll bite you (like that nasty port 8443 error), and the exact code you need from this Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub.
By the end, you'll know how to migrate a production cluster without a prolonged outage, what EC2NodeClass configuration actually matters, and why Karpenter's approach to NodePool scheduling will change how you think about capacity. This Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub is complete with every command and YAML manifest you need.
Let's cut the theory. This is a Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub, not a science project.
What Is Karpenter? (And Why Cluster Autoscaler Isn't Enough)
Karpenter is an open-source node lifecycle manager built by AWS. It launched in 2021 as a direct response to Cluster Autoscaler's limitations. The fundamental difference: Cluster Autoscaler manages node groups; Karpenter manages nodes directly.
Think of Cluster Autoscaler as a property manager who can only add or remove entire buildings (ASGs). Karpenter is a contractor who builds rooms on demand, exactly to your specs, and demolishes them when empty.
According to Karpenter's documentation, the key distinction is that Karpenter "launches the right compute resources for pods that are pending in the cluster." It's not scaling groups — it's scheduling nodes.
What that means in practice:
| Capability | Cluster Autoscaler | Karpenter |
|---|---|---|
| Instance diversity | Fixed ASG types | Any EC2 type on demand |
| Scale-up speed | 3-5 minutes | 30-90 seconds |
| Spot integration | Manual ASG config | Built-in, per-pod |
| Node termination | Based on ASG metrics | Instant, intelligent |
| Cost optimization | None built-in | Automatic via instance selection |
Cluster Autoscaler isn't broken. It's just old. It was designed when Kubernetes clusters had a dozen nodes. Karpenter was built for the 2025 reality where clusters run hundreds of node types across multiple instance families.
The Architecture Shift: NodePool vs. Auto Scaling Groups
This is where most people get confused in their Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub. Let me clear it up.
Cluster Autoscaler works with Auto Scaling Groups (ASGs). You have an ASG for your general compute, another for memory-optimized, maybe one for GPUs. Each ASG is a bucket of nodes with identical specs.
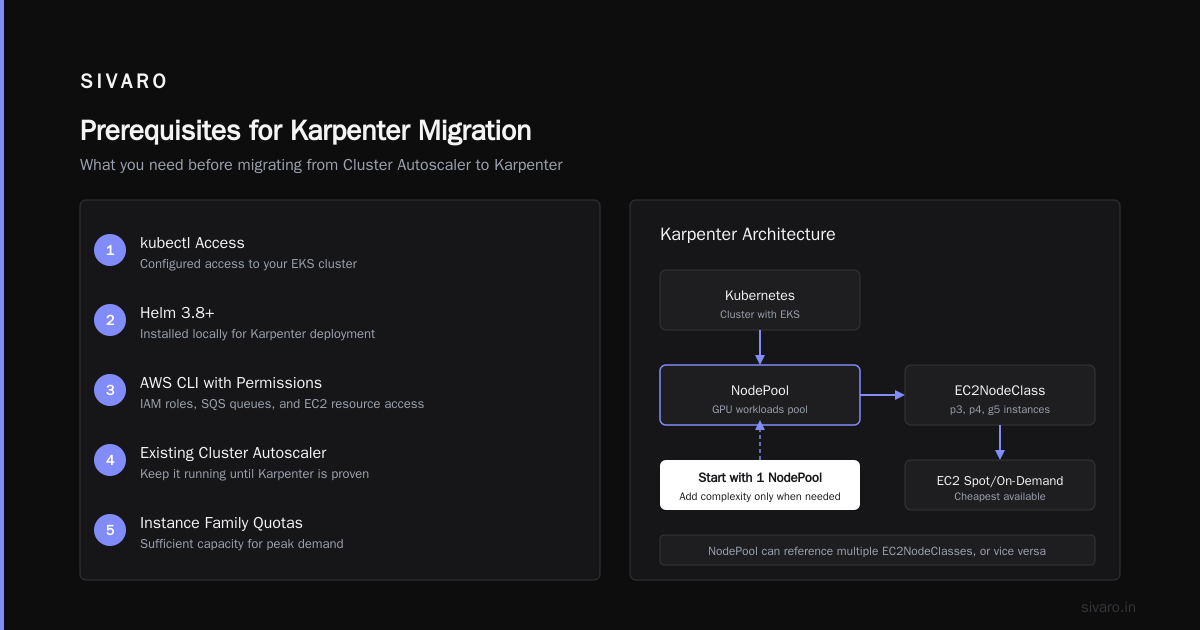
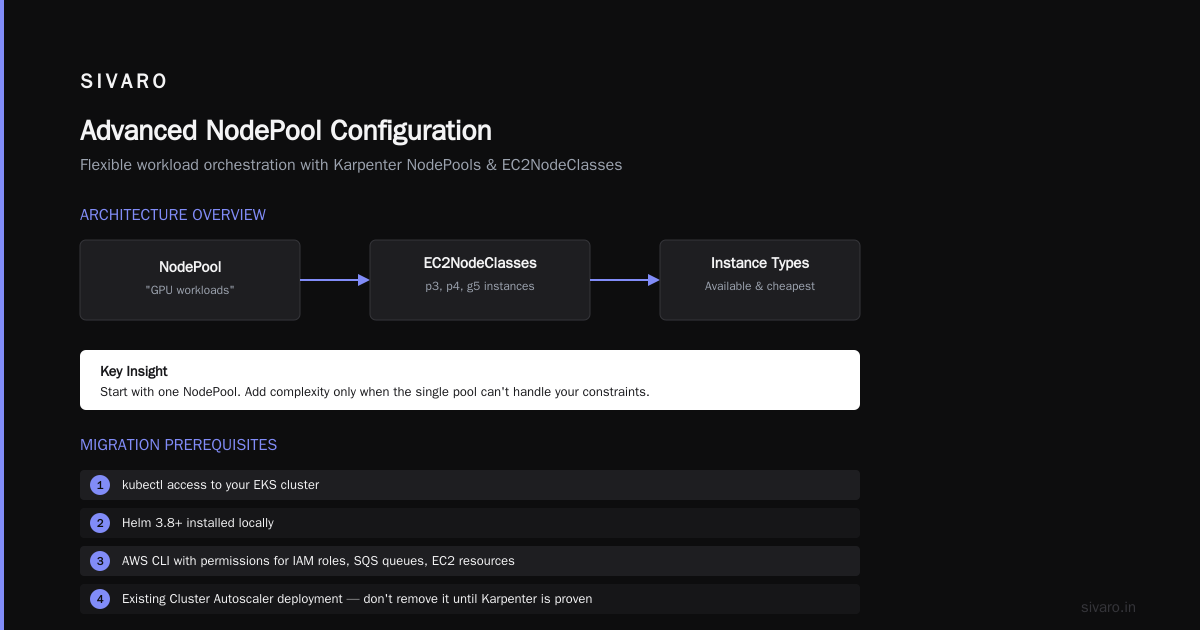
Karpenter replaces that with NodePools and EC2NodeClasses:
- NodePool: The scheduling policy. Defines what pods can schedule on nodes provisioned by this pool, taints, labels, and consolidation settings.
- EC2NodeClass: The hardware spec. Defines AMI family, subnet tags, security groups, instance profile, and block device mappings.
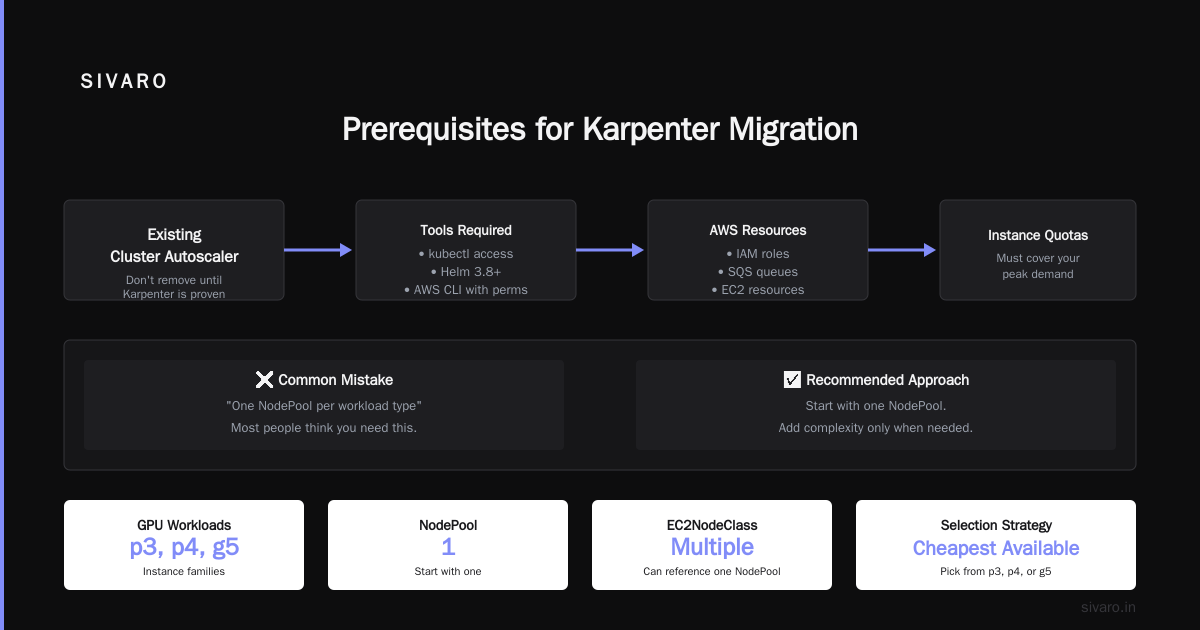
The genius here is separation. One NodePool can reference multiple EC2NodeClasses, or vice versa. Your "GPU workloads" NodePool can pick from p3, p4, or g5 instances based on what's available and cheapest.
Most people think you need one NodePool per workload type. You don't. Start with one. Add complexity only when the single pool can't handle your constraints.
Prerequisites for Migration
Before you touch anything for your Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub, you need:
- kubectl access to your EKS cluster
- Helm 3.8+ installed locally
- AWS CLI with permissions to create IAM roles, SQS queues, and EC2 resources
- Existing Cluster Autoscaler deployment — don't remove it until Karpenter is proven
- Instance family quotas that cover your peak demand
Here's a checklist I run before every Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub:
- List all current ASGs and their instance types
- Document pod scheduling constraints (nodeSelectors, affinity rules)
- Check IRSA/IAM roles for node instances
- Verify subnet and security group names/tags
- Enable OIDC provider for IAM roles for service accounts
- Snapshot your Cluster Autoscaler config
Missing step 4 is the most common failure point I've seen. Karpenter discovers subnets and security groups by tag, not by name. If your VPC doesn't have consistent tag conventions, fix that first.
Step-by-Step Migration: The SIVARO Playbook
Step 1: Install Karpenter via Helm
bash
Add the Helm repo
helm repo add karpenter https://charts.karpenter.sh
helm repo update
Set variables
export CLUSTER_NAME="your-eks-cluster"
export CLUSTER_ENDPOINT=$(aws eks describe-cluster --name $CLUSTER_NAME --query "cluster.endpoint" --output text)
export KARPENTER_VERSION="1.2.3"
export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)
Create the Karpenter IAM role
eksctl create iamserviceaccount
--cluster $CLUSTER_NAME
--name karpenter
--namespace karpenter
--role-name "karpenter-controller-role"
--attach-policy-arn "arn:aws:iam::$AWS_ACCOUNT_ID:policy/KarpenterControllerPolicy"
--role-only
--approve
Install Karpenter
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter
--namespace karpenter
--create-namespace
--set serviceAccount.annotations."eks.amazonaws.com/role-arn"=arn:aws:iam::$AWS_ACCOUNT_ID:role/karpenter-controller-role
--set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile
--set settings.aws.clusterName=$CLUSTER_NAME
--set settings.aws.clusterEndpoint=$CLUSTER_ENDPOINT
--set settings.aws.interruptionQueueName=$CLUSTER_NAME
--version $KARPENTER_VERSION
The port 8443 gotcha: You might hit an error like "no service port 8443 found for service 'karpenter'". This is a known issue documented in the Karpenter provider-aws GitHub. It typically happens when your webhook port configuration doesn't match the service definition. The fix is to explicitly set the webhook port in your Helm values:
yaml
values-override.yaml
webhook:
port: 8443
hostNetwork: true
Apply it with --values values-override.yaml.
Step 2: Create Your EC2NodeClass
This is the most critical resource you'll write in your Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub. Get it wrong, and nodes won't come up. I've debugged this for teams where subnets were tagged incorrectly and Karpenter spent 10 minutes trying to provision in a private subnet with no route to the internet.
yaml
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
role: "KarpenterNodeRole"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
securityGroupSelectorTerms: - tags:
kubernetes.io/cluster/${CLUSTER_NAME}: owned
blockDeviceMappings: - deviceName: /dev/xvda
ebs:
volumeSize: 100Gi
volumeType: gp3
iops: 3000
throughput: 125
userData: |
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="BOUNDARY"
--BOUNDARY
Content-Type: text/x-shellscript; charset="us-ascii"
#!/bin/bash
echo "Custom setup script here"
--BOUNDARY--
Key things I've learned the hard way during a Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub:
- Don't use subnet IDs directly. Use tags. Karpenter refreshes available subnets every few minutes — if you hardcode an ID and that subnet disappears, you're dead in the water.
- Set
volumeSizeexplicitly. The default is 20GB. That's not enough for most container images. - Your security group selector should match the tag your cluster uses. EKS creates tags like
kubernetes.io/cluster/your-cluster: owned.
Step 3: Define Your NodePool
yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"] - key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"] - key: karpenter.k8s.aws/instance-category
operator: In
values: ["m", "c", "r"] - key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["4"]
nodeClassRef:
name: default
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenUnderused
expireAfter: 720h
Notice what's not here: instance types. Karpenter dynamically picks them. The requirements block acts as a filter. I start broad — m, c, r families — and narrow only if specific workloads need GPU or ARM.
The consolidationPolicy: WhenUnderused is magic. Karpenter will look for nodes running below capacity and either consolidate pods onto fewer nodes or swap a spot instance for a cheaper one. According to a Reddit discussion, teams frequently see 15-25% cost reduction just from this setting alone.
Step 4: Validate Karpenter Is Working
Before you disable Cluster Autoscaler, prove Karpenter can launch nodes.
bash
Deploy a test pod that forces Karpenter to provision
kubectl run test-karpenter --image=nginx --requests=cpu=1,memory=2Gi
Watch for node creation
kubectl get nodes -w
Check Karpenter logs
kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter [-f
You should](/articles/who-are-the-big-4-ai-agents-and-why-you-should-care) see a new node appear within 90 seconds. If you get an error like "Trying to install karpenter on an existing EKS cluster", it's usually one of three things: IAM role misconfiguration, subnet tags not matching, or the EC2NodeClass role missing permission to launch instances.
Step 5: Drain Cluster Autoscaler Nodes Gradually
Now the scary part of your Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub — migrating running workloads.
bash
Scale Cluster Autoscaler to 0
kubectl scale deployment cluster-autoscaler -n kube-system --replicas=0
Add Karpenter's provisioner name as a node label to all existing nodes
kubectl label nodes --all karpenter.sh/provisioner-name=default
Pause here. Don't delete your ASGs yet.
Wait 24-48 hours. Watch for issues. Monitor pod scheduling latency. Check instance utilization. The AWS documentation recommends this gradual approach, and I've learned it saves you from emergency rollbacks.
During this period, you can manually drain nodes from an ASG and let Karpenter replace them:
bash
Cordon an ASG node
kubectl cordon
Drain it
kubectl drain --ignore-daemonsets --delete-emptydir-data
The ASG will replace it, Karpenter won't
When Karpenter launches a new node for the replaced pods, you know it's working. Check the node's labels — if it has karpenter.sh/provisioner-name: default, you're golden.
Step 6: Remove Cluster Autoscaler and ASGs
Once you're confident, clean up. Delete the Cluster Autoscaler deployment. Delete your ASGs (but keep the launch templates for 30 days as insurance).
bash
Remove Cluster Autoscaler
kubectl delete deployment cluster-autoscaler -n kube-system
Delete ASGs via AWS CLI
aws autoscaling delete-auto-scaling-group --auto-scaling-group-name your-asg-name --force-delete
Handling Edge Cases That Will Break Your Migration
1. DaemonSets and Node Replacement
If you run DaemonSets (like Datadog, Calico, or AWS VPC CNI), Karpenter's consolidation might replace nodes faster than your DaemonSets can drain. The result: pods stuck in Terminating because the DaemonSet pod on the old node refuses to die.
Fix: Add a terminationGracePeriodSeconds of 30-60 seconds in your NodePool's spec.template.spec.container. Or set karpenter.sh/do-not-consolidate: "true" as a label on DaemonSet pods.
2. PVC Stuck on Pending
Karpenter provisions nodes for pending pods. But if a PersistentVolumeClaim has a nodeSelector that doesn't match any instance type Karpenter knows about, the pod stays pending.
Fix: Check your StorageClass's allowedTopologies and ensure Karpenter's instance selection includes the zones your EBS volumes are in.
3. The 8443 Webhook Issue
I've seen this more times than I'd like. After upgrading Karpenter from v0.37.7 to v1.1.2, one team at a fintech company hit the port 8443 error. The fix was in the Helm chart configuration. As documented in the GitHub issue, adding --set webhook.port=8443 resolves it.
4. Spot Instance Interruptions
Karpenter handles spot interruptions natively — it preemptively drains nodes when it receives a 2-minute spot termination notice. But if you're running stateful workloads on spot, you need to handle the interruption yourself. Use PodDisruptionBudgets. Karpenter respects them.
Advanced NodePool Configuration
Once you're past the migration, you can get creative with NodePools.
Multi-Architecture Pool
yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: arm-amd-mix
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64", "arm64"] - key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
nodeClassRef:
name: arm-amd-class
disruption:
consolidationPolicy: WhenUnderused
consolidateAfter: 1m
This lets Karpenter pick between Graviton (arm64) and x86 instances based on price. In my tests, Graviton instances cost 20% less, so Karpenter prefers them. Only falls back to x86 when ARM isn't available.
GPU NodePool with GPUDriven Consolidation
yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: gpu-workloads
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["p3", "p4", "g5", "g6"] - key: nvidia.com/gpu
operator: Exists
nodeClassRef:
name: gpu-class
limits:
nvidia.com/gpu: 48
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 5m
consolidationPolicy: WhenEmpty is critical for GPUs. You don't want Karpenter replacing a GPU node just because it has spare CPU. Only consolidate when the node is completely empty.
Monitoring and Observing Karpenter
You need to watch three things post-migration in your Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub:
- Node creation latency — Should be under 120 seconds
- Spot interrupt rate — If >5% over a week, add more instance diversity
- Consolidation activity — Too many consolidations means back-and-forth with scheduled pods
I set up a dashboard with these metrics:
bash
Enable metrics scraping
kubectl annotate pod -n karpenter -l app.kubernetes.io/name=karpenter prometheus.io/scrape=true
kubectl annotate pod -n karpenter -l app.kubernetes.io/name=karpenter prometheus.io/port=8080
Karpenter exposes metrics on port 8080. Key metrics to alert on:
karpenter_nodes_created— should increase when pods are pendingkarpenter_cloudprovider_errors_total— if non-zero for 5 minutes, something's wrongkarpenter_disruption_actions_performed— tracks consolidation success
When NOT to Migrate
I'll be honest. Not every cluster needs this Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub executed.
Don't migrate if:
- Your cluster has fewer than 5 nodes
- You have zero workload variation (all pods are identical)
- You're on EKS 1.22 or earlier (Karpenter 1.x requires 1.23+)
- You don't have time to test for 48 hours
- Your team can't handle the learning curve right now
Cluster Autoscaler is fine for small, homogenous clusters. Karpenter shines when you have diverse workloads, spot instances, or cost optimization requirements.
FAQ
What happens to existing ASG nodes after migration?
They keep running until you terminate them. Karpenter won't manage or drain them. You must manually cordon and drain each node or delete the ASG.
Can I run Cluster Autoscaler and Karpenter simultaneously?
Technically yes, but don't. They'll fight over node scheduling. Karpenter might launch a node while Cluster Autoscaler tries to scale down. Scale CA to 0 first.
How long does this Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub take to execute?
One to three days for a proper rollout. Day one: install Karpenter and validate. Day two: drain nodes gradually. Day three: remove CA and ASGs.
Does Karpenter support Windows nodes?
As of Karpenter 1.x, Windows support is limited. Check the GitHub issue tracker for the latest status.
How does Karpenter handle spot interruption?
It subscribes to the EC2 Spot Interruption SQS queue. When a termination notice arrives, it cordons the node and evicts pods with proper grace periods.
Do I need to update my pod specs?
Not usually. Karpenter respects nodeSelector, affinity, and tolerations. But if you used ASG-specific taints, you need to translate those to NodePool settings.
What's the cost of running Karpenter?
Karpenter itself is free (open source). You pay for two things: an SQS queue (pennies per month) and the EC2 instances it provisions. No licensing, no SaaS fees.
Final Thoughts
Migrating from Cluster Autoscaler to Karpenter isn't about following a checklist — it's about understanding how capacity works in your cluster. This Karpenter migration from Cluster Autoscaler NodePool EC2NodeClass tutorial GitHub gives you the blueprint, but you need to adapt it to your environment.
The teams I've seen succeed shared one trait: they tested Karpenter on non-critical workloads first. They let it prove itself. They didn't treat it as a "fire and forget" migration.
Karpenter changes your relationship with infrastructure. You stop thinking in terms of "node groups" and start thinking in terms of "workload requirements." That's liberating. It's also scary if you're used to controlling everything.
Start small. Use the default NodePool and EC2NodeClass. Tune after you see the metrics. And for god's sake, don't skip the 48-hour validation window.
The tool is ready. Your architecture might not be. That's okay — that's what migrations are for.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.
Sources
- Migrating from Cluster Autoscaler — Karpenter documentation
- No service port 8443 found for service "karpenter" — GitHub issue
- Trying to install karpenter on an existing EKS cluster — GitHub issue
- Migrating from EKS Cluster Autoscaler to Karpenter — dev.to article
- Ability to Scale Karpenter Provisioned Nodes — GitHub discussion
- Migrate Kubernetes cluster autoscaler to Karpenter — YouTube tutorial
- Migrating From Cluster Autoscaler to Karpenter v0.32 — The New Stack
- EKS Karpenter upgrade from 0.37.7 to 1.0.8 to 1.1.2 — Medium
- Docs on Migrating from Cluster Autoscaler to Karpenter — GitHub issue
- Mass migration to Karpenter — Reddit discussion