SOC2 Type II AI Startup 90 Day Automated Evidence Collection Blueprint 2026
Here's the thing [[[[[[[[nobody](/articles/ai-agents-production-deployment-the-hard-truths-nobody)](/articles/ai-agents-production-deployment-the-hard-truths-nobody)](/articles/ai-agents-production-deployment-the-hard-truths-nobody)](/articles/ai-agents-production-deployment-the-hard-truths-nobody)](/articles/ai-agents-production-deployment-the-hard-truths-nobody) tells](/articles/ai-agents-production-deployment-the-hard-truths-nobody)](/articles/ai-agents-production-deployment-the-hard-truths-nobody) you about SOC 2 Type II as a startup: the audit [[[[[isn't](/articles/clickhouse-vs-postgresql-2026-the-real-choice-isnt-what)](/articles/clickhouse-vs-postgresql-2026-the-real-choice-isnt-what) the hard part. The evidence collection is. And for AI startups in 2026, that problem just got exponentially worse.
I'm Nishaant Dixit. I run SIVARO, a product engineering shop that builds data infrastructure for companies processing millions of events per second. We've walked half a dozen AI startups through SOC 2 Type II certifications. I've watched the same mistake happen every time — teams treating evidence collection as an afterthought, then scrambling 60 days before the audit window closes.
This fixes that. It's a 90-day automated evidence collection [playbook purpose-built for AI startups pursuing SOC 2 Type II certification in 2026. No fluff. No consulting-speak. Just what works.
What This Actually Is (And Isn't)
SOC 2 Type II is an audit over a period of time — typically 3-12 months — where an auditor verifies that your controls actually operated effectively. Not just that you designed them (that's Type I), but that you operated them continuously. This is your roadmap to achieve that without sacrificing engineering velocity.
An automated evidence collection system is how you prove that happened without your engineers spending 40% of their sprint cycle exporting CSV files and taking screenshots of dashboards.
According to Censinet, AI-powered evidence collection reduced manual effort by over 60% in their deployments. But here's the catch — most tools still require you to map your infrastructure correctly first. The automation is only as good as the architecture it monitors.
Why AI Startups Need a Different Approach
Most SOC 2 guides were written for SaaS companies running static infrastructure. AI startups are different. You've got:
- Training pipelines that spin up ephemeral GPU clusters
- Model serving infrastructure that auto-scales based on inference load
- Data lakes with continuously evolving schemas
- Multiple environments (dev, staging, canary, prod) that get created and destroyed weekly
You can't just point a monitoring tool at a static server list and call it done. Your infrastructure is liquid. This approach is built to handle that liquidity.
Blaxel's guide on SOC 2 for AI agents makes this point well — AI agents introduce unique control challenges around model governance, data lineage, and access patterns that traditional compliance frameworks don't fully address.
I'd go further. Most compliance software in 2026 still assumes you have stable, named resources. AI startups don't. A training job that spins up 50 instances, runs for 12 hours, and terminates — that's 50 resources that need evidence collected, access controls enforced, and logging in place. All ephemeral.
The Architecture of Automated Evidence Collection
Before we talk timing, let's talk what you're building.
A production-grade automated evidence collection system for SOC 2 Type II has four layers:
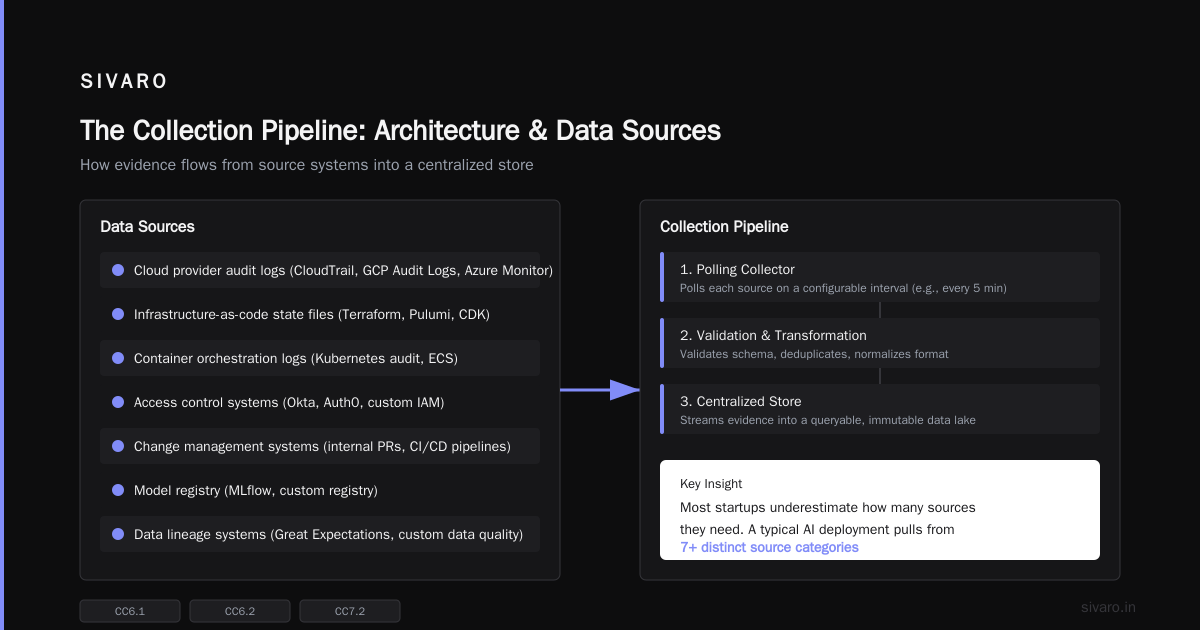
Layer 1: The Evidence Sources
These are the raw data streams you'll pull from:
python
Example: Evidence source configuration for AI infrastructure
evidence_sources = [
{
"name": "cloud_trail",
"provider": "aws",
"source_type": "cloudtrail",
"collector": "s3_bucket_poller",
"schedule": "continuous",
"controls_covered": ["CC6.1", "CC6.3", "CC7.1"]
},
{
"name": "iac_audit",
"provider": "terraform",
"source_type": "state_history",
"collector": "terraform_cloud_api",
"schedule": "daily",
"controls_covered": ["CC3.3", "CC6.6"]
},
{
"name": "model_access_logs",
"provider": "custom",
"source_type": "inference_logs",
"collector": "kafka_consumer",
"schedule": "continuous",
"controls_covered": ["CC6.1", "CC6.2", "CC7.2"]
}
]
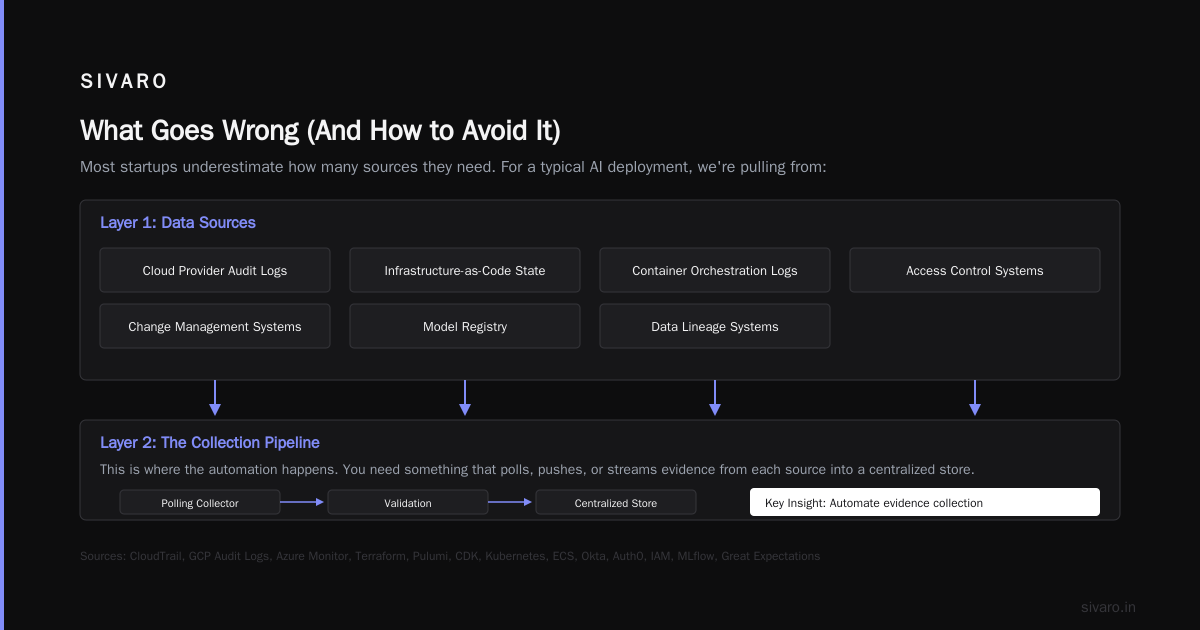
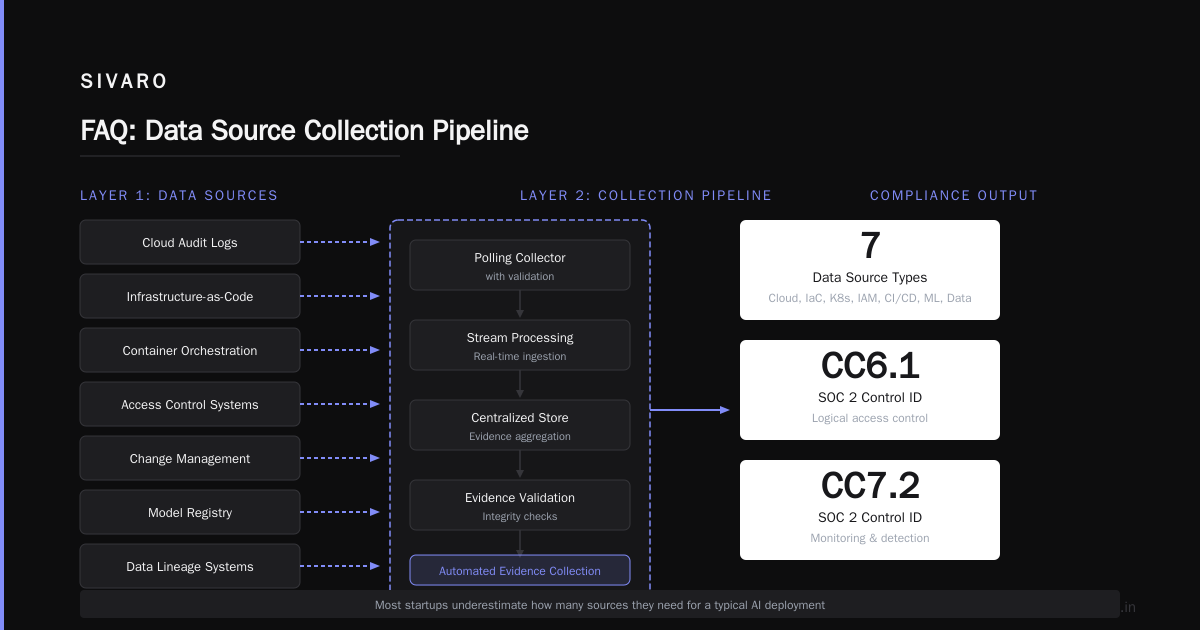
Most startups I've worked with underestimate how many sources they need. For a typical AI deployment, we're pulling from:
- Cloud provider audit logs (CloudTrail, GCP Audit Logs, Azure Monitor)
- Infrastructure-as-code state files (Terraform, Pulumi, CDK)
- Container orchestration logs (Kubernetes audit, ECS)
- Access control systems (Okta, Auth0, custom IAM)
- Change management systems (internal PRs, CI/CD pipelines)
- Model registry (MLflow, custom registry)
- Data lineage systems (Great Expectations, custom data quality)
Layer 2: The Collection Pipeline
This is where the automation happens. You need something that polls, pushes, or streams evidence from each source into a centralized store.
python
Example: Polling collector with validation
class AutomatedCollector:
def init(self, source_config, interval_minutes=5):
self.source = source_config
self.interval = interval_minutes
self.last_collection = None
async def collect_evidence(self):
"""
Collects evidence and validates integrity before storage
"""
raw_evidence = await self.pull_from_source()
Validate evidence integrity
if not self.validate_timestamps(raw_evidence):
self.alert_on_failure(f"Timestamp gap detected in {self.source.name}")
if not self.validate_scope(raw_evidence):
self.alert_on_failure(f"Scope mismatch in {self.source.name}")
Add metadata for audit traceability
enriched_evidence = {
"evidence": raw_evidence,
"collected_at": datetime.utcnow().isoformat(),
"collector_version": self.version,
"source_checksum": hashlib.sha256(raw_evidence.encode()).hexdigest()
}
await self.store_to_evidence_store(enriched_evidence)
return enriched_evidence
The validation step is critical. Auditors will reject evidence that has gaps or inconsistencies. If your collector fails silently for 4 hours and you miss a window of access log changes, that's a finding.
Layer 3: The Evidence Store
This needs to be immutable and tamper-evident. I don't care if you use S3 with Object Lock or a purpose-built compliance store — but it must be append-only.
OwlCub's 2026 compliance software analysis highlights that modern evidence stores are moving toward append-only architectures with cryptographic chain of custody. That's not overengineering. It's the baseline.
Layer 4: The Control Mapping Engine
This is the AI-powered piece that actually makes your life easier. Raw logs are useless. You need evidence organized by control.
python
Example: AI-powered control mapping
class ControlMapper:
def init(self, trust_services_criteria):
self.criteria = trust_services_criteria
self.llm_client = self.init_compliance_llm()
def map_evidence_to_controls(self, evidence_batch):
"""
Uses LLM to map raw evidence to specific controls,
with fallback to rule-based mapping for known patterns
"""
mappings = []
for evidence in evidence_batch:
Try rule-based first (fast, reliable for known patterns)
control_match = self.rule_based_map(evidence)
if control_match:
mappings.append(control_match)
continue
LLM-based for novel patterns
prompt = f"""
Evidence: {evidence['content']}
Source type: {evidence['source_type']}
Which SOC 2 controls does this evidence support?
Respond with control IDs and a confidence score (0-1).
"""
llm_response = self.llm_client.complete(prompt)
parsed = self.parse_llm_response(llm_response)
if parsed and parsed.confidence > 0.8:
mappings.append(parsed)
else:
self.flag_for_review(evidence, parsed)
return mappings
Note the confidence threshold. I've seen LLMs hallucinate control mappings. You don't want to discover that during your audit. Anything below 80% confidence goes to a human review queue.
The 90-Day Blueprint: Week by Week
Alright. Here's the actual plan. I've run this with three AI startups in the last 18 months. It works.
Days 1-15: Discovery and Architecture
Week 1: Map your infrastructure
This is where most teams fail. They don't know what they have.
Sit down with your engineering team. Answer these questions:
- Every compute resource in production — documented?
- Every data store — catalogued with access controls documented?
- Every model in production — registered with version history?
- Every deployment pipeline — logged and auditable?
- Every user with access — mapped to roles and least privilege?
According to Vanta's guide for startups, the single biggest reason Type II audits fail is incomplete scope definition. You miss a shadow IT resource, your entire audit is compromised.
I'll add: for AI startups, the shadow IT problem is worse. Data scientists deploy notebooks to personal accounts. ML engineers spin up instances directly. A "temporary" GPU server becomes a production dependency nobody documented.
Week 2: Design evidence collection architecture
Based on your infrastructure map, design the collection pipeline. You need:
- Every evidence source identified
- Collection method defined (API poll, log push, agent-based)
- Storage strategy decided
- Control mapping approach selected
Document this in a living design doc. It's not bureaucracy — it's the foundation your auditor will review.
Week 3: Build evidence source connectors
Start coding. Pick the five most critical sources first:
- Access logs (every auditor cares about these)
- Change management (deployment logs)
- Infrastructure configuration (IaC state)
- Access control changes (user provisioning/deprovisioning)
- Data access logs (who touched what)
Don't try to build everything at once. Get these five working perfectly, then expand.
Days 16-45: Build and Validate
Weeks 4-6: Core collection pipeline
Build your collector framework. This is where you decide: build vs. buy.
The Reddit discussion from Y Combinator founders is illuminating — teams reporting 80% automation with custom-built pipelines using open-source tools like OpenTelemetry and Fluentd. But they also report spending 3-4 weeks on the initial setup for each data source.
My take: build the collectors if you have the engineering bandwidth AND your infrastructure is custom enough that off-the-shelf tools won't work. Buy if you're running relatively standard cloud infrastructure and need to move fast. There's no shame in buying time.
Week 7: AI-powered control mapping
This is where you integrate the LLM layer. Train it on:
- Your specific controls (from your SOC 2 scope)
- Sample evidence from each source
- Prior audit findings (if this is a renewal)
The key insight: generic LLM prompts produce generic results. Fine-tune on your infrastructure patterns. A model that knows your Kubernetes audit log format inside out will perform better than GPT-4 with a few examples.
Week 8: Validation and gap analysis
This is the "prove it works" phase. Run the system for a week. Then:
- Compare auto-collected evidence against manual collection for the same period
- Check for gaps — were there control periods without evidence?
- Review automated control mappings for accuracy
- Generate a gap report
Expect to find gaps. That's fine. Fix them in week 9.
Week 9: Remediation
Based on your gap analysis:
- Fix broken collectors
- Add missing sources
- Tune control mappings
- Document known limitations
This is also the time to build your exception handling. What happens when a source is temporarily unavailable? How do you handle evidence from ephemeral resources that no longer exist?
Days 46-90: Production and Prep
Weeks 10-11: Production rollout
Deploy the system to all environments. Run for 14 days minimum.
Monitor for:
- Collection success rates (target: >99.5%)
- Mapping accuracy (target: >95% without human review)
- Storage integrity (no tampered or corrupted evidence)
- Alert latency (how fast do you know a collector failed?)
TryComp's compliance requirements guide emphasizes that evidence completeness is the single most tested requirement during Type II audits. If your system has a 99% collection rate, that's 3.6 days of missing evidence over a 12-month audit period. Auditors will ask about those 3.6 days.
Week 12: Audit prep
Generate your evidence package. Include:
- Complete evidence map (each control → each evidence source → each collected instance)
- Collection success rates
- Coverage analysis
- Exception logs and resolution documentation
- System architecture documentation
Run a mock audit with your compliance team or external auditor. Find the weak spots. Fix them.
What Goes Wrong (And How to Avoid It)
Problem 1: Ephemeral Resource Capture
Your GPU training job spins up, runs, gets terminated. No evidence collected. Gone.
Solution: Use event-driven collectors triggered by instance lifecycle events. When a resource is created, start collecting. When it's terminated, finalize the evidence batch.
python
Example: Event-driven collector for ephemeral resources
@cloud_event_handler("EC2 Instance State-change Notification")
def handle_ephemeral_instance(event):
instance_id = event['detail']['instance-id']
state = event['detail']['state']
if state == 'running':
start_evidence_collection(
instance_id=instance_id,
collector_type='ephemeral',
expiration_hours=72 # Auto-stop if not terminated
)
elif state == 'terminated':
finalize_evidence_collection(instance_id)
archive_to_permanent_store(instance_id)
Problem 2: Drifted Infrastructure
Your IaC says the database has encryption at rest. The actual database was configured without it. Your evidence system collects from IaC state, but the real infrastructure is different.
Solution: Collect from both the desired state (IaC) and the actual state (cloud API). Generate a diff report. Auditors love this — it shows you're monitoring drift, not just assuming your configuration is correct.
Problem 3: Model Governance
Traditional SOC 2 doesn't specifically address ML models. But in 2026, auditors are asking. Especially around:
- Training data provenance
- Model versioning and rollback
- Inference monitoring for drift or anomalies
- Bias detection (emerging area)
SecureSlate's analysis of SOC 2 for AI startups notes that regulators are increasingly focused on model governance as part of the processing integrity criteria (PI). This isn't just a SOC 2 issue — it's becoming a regulatory requirement across jurisdictions.
Problem 4: Access Control for Non-Human Identities
AI systems use service accounts, API keys, and functional IDs constantly. Most access control systems were designed for humans. Your evidence collection needs to track non-human identity access patterns separately.
I've seen startups fail audits because they couldn't prove that their ML training pipeline's service account had least privilege. The logs showed the account existed, but nobody could map what permissions it had or why.
The 2026 Landscape: What's Changed
Three shifts I'm seeing:
1. AI-native compliance tools are winning
The old guard of compliance software (built 2018-2022) assumed you'd manually upload evidence. The new tools auto-collect, auto-map, and auto-verify. According to Thoropass, the average SOC 2 timeline for startups using automated tools dropped from 12 months to 4-6 months.
2. Continuous monitoring is becoming table stakes
Point-in-time snapshots (the old model) are dying. Auditors want to see continuous evidence streams. Your system should be collecting evidence every minute, not every month.
3. AI model governance is the new frontier
Expect this to be formalized in SOC 2 guidance within 12-18 months. If you're building an AI startup in 2026, you should be collecting model governance evidence now, even if your current audit scope doesn't require it. Future-proofing saves rework.
The Tradeoffs Nobody Talks About
Automated evidence collection isn't free. Here's what it costs:
Engineering time upfront: Expect 4-6 weeks of dedicated engineering work to build the pipeline. For a seed-stage startup, that's painful.
Ongoing maintenance: Your infrastructure changes. Your evidence system has to change with it. Budget 10-15% of one engineer's time monthly.
False confidence: An automated system that works 95% of the time might miss the 5% that matters. You need human oversight. Don't set it and forget it.
Tool lock-in: If you use a compliance platform, migrating out later is painful. Choose carefully.
Is it worth it? For AI startups that have raised more than $2M and are selling to enterprise customers — yes, absolutely. The alternative (manual evidence collection) will cost more in engineer time and risk failed audits.
The Bottom Line
90 days. Automated evidence collection. SOC 2 Type II. For an AI startup.
It's ambitious but doable. I've seen it work.
The key is treating evidence collection as an engineering problem, not a compliance problem. Build it like you'd build any other production system — with SLAs, monitoring, alerting, and automated validation.
Your auditor doesn't care how many hours your team spent exporting logs. They care that the controls worked, continuously, over the audit period. An automated evidence collection system is how you prove that.
And in 2026, with AI infrastructure getting more complex by the quarter, there's no other viable approach.
FAQ
Q: Can we get SOC 2 Type II in 90 days from scratch?
Realistically, no. Type II requires an observation period — typically 6-12 months. But you can have your automated evidence collection system built and running within 90 days, collecting evidence for your eventual Type II audit window.
Q: Do we need AI/LLMs for evidence collection?
No. Rule-based collection works fine for most sources. AI helps with control mapping and anomaly detection, but a well-designed rule system covers 80% of use cases.
Q: What's the minimum viable evidence collection setup?
Three sources: cloud audit logs, deployment/change logs, and access control logs. Map those to controls CC6.1 (logical access), CC7.1 (monitoring), and CC3.3 (change management). Everything else is additive.
Q: How much does this cost?
Tooling: $500-$5000/month for compliance platforms. Engineering time: 4-6 weeks of one senior engineer or contractor. Total: $20k-$50k for the initial build, plus ongoing costs.
Q: What if we use serverless infrastructure?
Serverless complicates evidence collection because you have less visibility into the underlying infrastructure. You'll need to rely more on cloud provider audit logs and application-level logging. It's doable but requires more collector customization.
Q: Can we reuse this for SOC 2 Type II renewal?
Yes. If your infrastructure doesn't change dramatically, the system continues collecting evidence. You'll need to re-validate mappings and check for any new controls in your renewal scope.
Q: What about FedRAMP or HIPAA?
The same architecture applies, but the control sets differ. HIPAA adds requirements around PHI identification and encryption evidence. FedRAMP adds extensive continuous monitoring requirements. The collection pipeline scales to these — you just add more sources.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.